I have a dataframe like as below
df = pd.DataFrame(
{'stud_id' : [101, 101, 101, 101,
101, 101, 101, 101],
'sub_code' : ['CSE01', 'CSE01', 'CSE01',
'CSE01', 'CSE02', 'CSE02',
'CSE02', 'CSE02'],
'ques_date' : ['13/11/2020', '10/1/2018','11/11/2017', '27/03/2016',
'13/05/2010', '10/11/2008','11/1/2007', '27/02/2006'],
'marks' : [77, 86, 55, 90,
65, 90, 80, 67]}
)
df['ques_date'] = pd.to_datetime(df['ques_date'])
I would like to do the below
a) group the data by stud_id and sub_code
b) Compute the mean difference ques_date for each group
c) Compute the count of marks for each group
So, I tried the below and it works fine
df['avg_ques_gap'] = (df.groupby(['stud_id','sub_code'])['ques_date']
.transform(lambda x: x.diff().dt.days.median()))
output = df.groupby(['stud_id','sub_code']).agg(last_ques_date=('ques_date','max'),
total_pos_transactions=('marks','count')).reset_index()
But you can see that I write two lines. one for transform and other for aggregate function.
Is there anyway to write both transform and aggregate in single line?
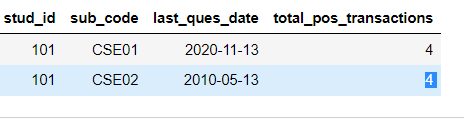
I expect my ouptut to be like as below
CodePudding user response:
Because there is added median lambda function aggregate values, so possible add to named aggregation:
f = lambda x: x.diff().dt.days.median()
output = (df.groupby(['stud_id','sub_code'], as_index=False)
.agg(last_ques_date=('ques_date','max'),
total_pos_transactions=('marks','count'),
avg_ques_gap = ('ques_date',f)))
print (output)
stud_id sub_code last_ques_date total_pos_transactions avg_ques_gap
0 101 CSE01 2020-11-13 4 -594.0
1 101 CSE02 2010-05-13 4 -579.0