Data skew is something that hapen offen, that should be detected and treated correctly, I'm able to detect data skew in specific table using a groupby/count query in the joining key, however I have multiple joins in my application and doing that for each join can take time.
So is it possible to detect data skew directlly in the spark web ui which will saves me time ?
CodePudding user response:
Data skew mean that you will have partitions that are significantly bigger than some other partitions.
For me, I usually check 2 things, In the stage tab, sort by decreasing duration, then click on tasks that are slow:
1- Check Summary Metrics which is one of the most important parts of the Spark UI. It gives you information about how your data is distributed among your partitions.
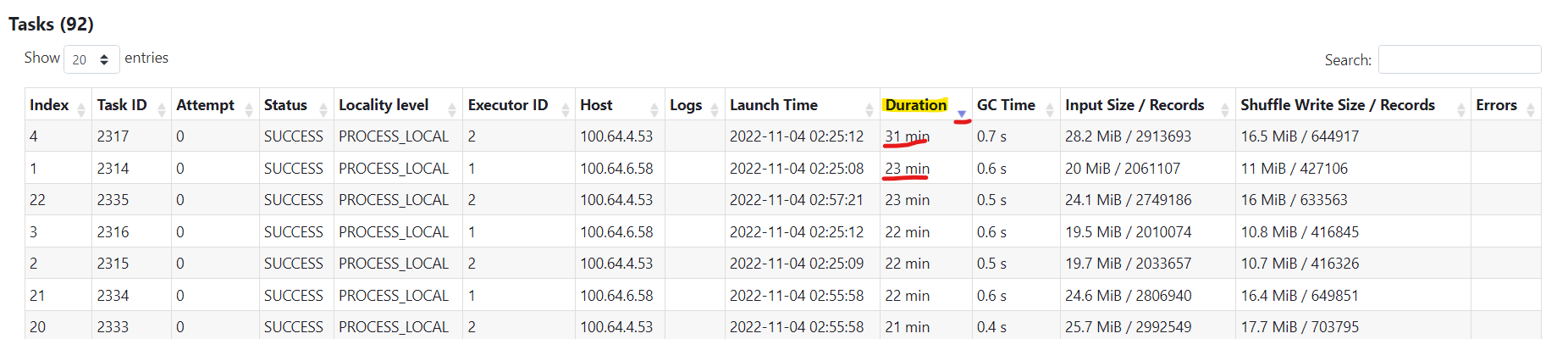
So to detect skew you can compare duration in Median and in Max columns, ideally the 2 values should be the same, when the difference between the two is bigger than defiantly there's a data skew, for example in the below picture:

Which means some tasks in that stage are taking too much time (31min) compared to other that takes only 1.1 minutes because of partitions size imbalance, the Min duration is also low which indicates that some partitions are nearly empty.
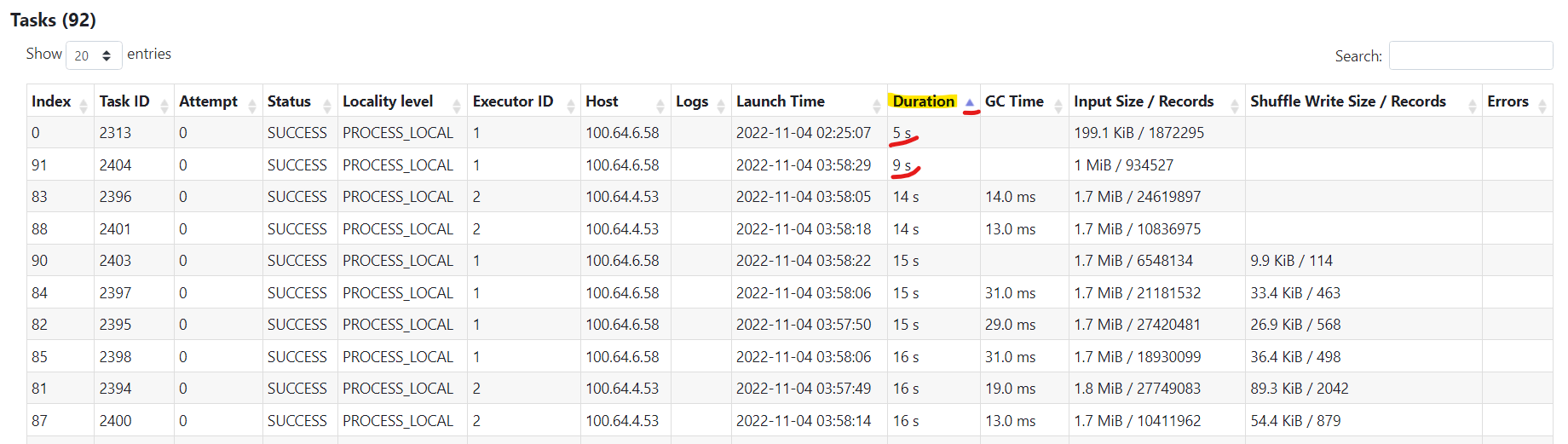
2- In the bottom of the stage You can find all tasks related to that stage, sort them by decreasing duration, then by Increasing duration, make sure that min duration and max duration are close if not than there are skewed in the you partitions, like in the picture below: