I decided to use BeautifulSoup for extracting string integers from Pandas column. BeautifulSoup works well applied on a simple example, however, does not work for a list column in Pandas. I cannot find any mistake. Can you help?
Input:
df = pd.DataFrame({
"col1":[["<span style='color: red;'>9</span>", "abcd"], ["a", "b, d"], ["a, b, z, x, y"], ["a, y","y, z, b"]],
"col2":[0, 1, 0, 1],
})
for list in df["col1"]:
for item in list:
if "span" in item:
soup = BeautifulSoup(item, features = "lxml")
item = soup.get_text()
else:
None
print(df)
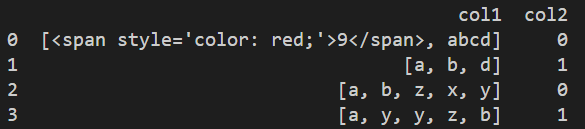
Desired output:
df = pd.DataFrame({
"col1":[["9", "abcd"], ["a", "b, d"], ["a, b, z, x, y"], ["a, y","y, z, b"]],
"col2":[0, 1, 0, 1],
})
CodePudding user response:
You are trying to iterate using a for loop on the Series, but when working with Pandas it's preferred and simpler to apply a function instead, like this:
def extract_text(lst):
new_lst = []
for item in lst:
if "span" in item:
new_lst.append(BeautifulSoup(item, features="lxml").text)
else:
new_lst.append(item)
return new_lst
df['col1'] = df['col1'].apply(extract_text)
Or you could one-line it using list comprehension:
df['col1'] = df['col1'].apply(
lambda lst: [BeautifulSoup(item, features = "lxml").text if "span" in item else item for item in lst]
)
CodePudding user response:
This will apply the extract_integer function to each element of the col1 column, replacing the original value with the extracted integer if the element contains the "span" tag, or leaving the value unchanged if it doesn't.
def extract_integer(item):
if "span" in item:
soup = BeautifulSoup(item, features = "lxml")
return soup.get_text()
return item
df = pd.DataFrame({
"col1":[["<span style='color: red;'>9</span>", "abcd"], ["a", "b, d"], ["a, b, z, x, y"], ["a, y","y, z, b"]],
"col2":[0, 1, 0, 1],
})
df["col1"] = df["col1"].apply(lambda x: [extract_integer(item) for item in x])
print(df)
Output:
col1 col2
0 [9, abcd] 0
1 [a, b, d] 1
2 [a, b, z, x, y] 0
3 [a, y, y, z, b] 1