I am getting this error: y should be a 1d array, got an array of shape (1, 10) instead.
filename="UrbanSound8K/car_horn.wav"
audio, sample_rate = librosa.load(filename, res_type='kaiser_fast')
mfccs_features = librosa.feature.mfcc(y=audio, sr=sample_rate, n_mfcc=40)
mfccs_scaled_features = np.mean(mfccs_features.T,axis=0)
print(mfccs_scaled_features)
mfccs_scaled_features=mfccs_scaled_features.reshape(1,-1)
print(mfccs_scaled_features)
print(mfccs_scaled_features.shape)
predicted_label=model.predict(mfccs_scaled_features)
print(predicted_label)
prediction_class = labelencoder.inverse_transform(predicted_label)
prediction_class
Error image:

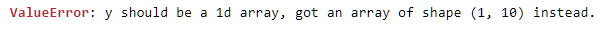
CodePudding user response:
1D array and a 2D array with shape (1,10) are two different things. The 2nd one is a 2D array where number of rows happen to be 1.
They are interconvertible.
y=np.random.uniform(0,1,size=[1,10]) #Random array of shape (1,10)
y_oned=y.reshape(10) #Reshaping it into a 1D array
print(y_oned.shape)
Output
(10,) which is what you need.
CodePudding user response:
You can squeeze the shape of predicted_label from (1,10) to (10,) by using np.squeeze. Replace your offending line with below code.
prediction_class =labelencoder.inverse_transform(np.squeeze(predicted_label))