I have a PySpark DataFrame and I want to map values of a column.
Sample dataset:
data = [(1, 'N'), \
(2, 'N'), \
(3, 'C'), \
(4, 'S'), \
(5, 'North'), \
(6, 'Central'), \
(7, 'Central'), \
(8, 'South')
]
columns = ["ID", "City"]
df = spark.createDataFrame(data = data, schema = columns)

The mapping dictionary is:
{'N': 'North', 'C': 'Central', 'S': 'South'}
And I use the following code:
from pyspark.sql import functions as F
from itertools import chain
mapping_dict = {'N': 'North', 'C': 'Central', 'S': 'South'}
mapping_expr = F.create_map([F.lit(x) for x in chain(*mapping_dict.items())])
df_new = df.withColumn('City_New', mapping_expr[df['City']])
And the results are:
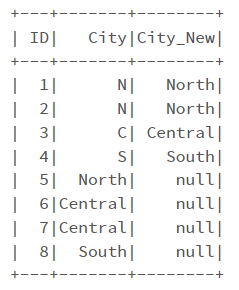
As you can see, I get Null values for rows which I don't include their values in the mapping dictionary. To solve this, I can define mapping dictionary by:
{'N': 'North', 'C': 'Central', 'S': 'South', \
'North': 'North', 'Central': 'Central', 'South': 'South'}
However, if there are many unique values in the dataset, it is hard to define a mapping dictionary.
Is there any better way for this purpose?
CodePudding user response:
you can use a coalesce.
here's how it'd look like.
# create separate case whens for each key-value pair
map_whens = [func.when(func.upper('city') == k.upper(), v) for k, v in map_dict.items()]
# [Column<'CASE WHEN (upper(city) = N) THEN North END'>,
# Column<'CASE WHEN (upper(city) = C) THEN Central END'>,
# Column<'CASE WHEN (upper(city) = S) THEN South END'>]
# pass case whens to coalesce with last value as `city` field
data_sdf. \
withColumn('city_new', func.coalesce(*map_whens, 'city')). \
show()
# --- ------- --------
# | id| city|city_new|
# --- ------- --------
# | 1| N| North|
# | 2| N| North|
# | 3| C| Central|
# | 4| S| South|
# | 5| North| North|
# | 6|Central| Central|
# | 7|Central| Central|
# | 8| South| South|
# --- ------- --------