I want to read particular lines from the text file. E.g. all the contents between "This contents information"
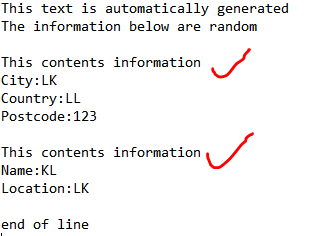
I have created a script to perform the task, but it's not a good method. Are there any better way to do it?
readText=open("test.txt","r")
wanted_lines = [4,5,6,7]
count = 1
with open('test.txt', 'r') as infile:
for line in infile:
line = line.strip()
if count in wanted_lines:
print(line)
else:
pass
count = 1
CodePudding user response:
You can compare each line to the sentinel, start outputting once it matches, and stop outputting once it matches again:
with open('test.txt') as infile:
for output in False, True:
for line in map(str.rstrip, infile):
if line == 'This contents information':
break
if output:
print(line)
Demo: https://replit.com/@blhsing/TroubledMysteriousMonitors
CodePudding user response:
You could consider reading the entire text file into a string, and then using a regular expression to extract the contents you want:
with open('test.txt', 'r') as file:
data = file.read()
contents = re.search(r'^This contents information\n(.*?)\nThis contents information\b', inp, flags=re.M|re.S).group(1)
print(contents)
This prints:
City:LK
Country:LL
Postcode:123
CodePudding user response:
You can use split, with "This contents information" as the delimiter.
In the example above, the file will be split into 3 sections, of which we only need to grab the second one (index=1). You can then use .strip() to remove unwanted space.
Code:
with open('test.txt', 'r') as infile:
text = infile.read()
required_info = text.split("This contents information")[1].strip()
print(required_info)
Output:
City:LK
Country: LL
Postcode:123
CodePudding user response:
Instead of prewriting the line numbers, just have a conditional statement that checks for the data you want.
readText=open("test.txt","r")
with open('test.txt', 'r') as infile:
for line in infile:
line = line.strip()
if line == "text to look for":
printline = True
elif line == "text to end content":
printline = False
elif printline == True:
print(line)
CodePudding user response:
I think the best method would be to use regex.
import re
text=""
with open('test.txt', 'r') as infile:
text = infile.read()
# Don't forget to replace here with the word you want to search among what you want to find.
# This contents information(.*?)\nThis contents information
# this regex finds everything between these two words
# example: 'test 123asda test' -> test(.*?)test => ' 123asda '
regex = re.compile(r'This contents information(.*?)\nThis contents information', re.DOTALL)
matches = [m.groups()[0] for m in regex.finditer(text)]
for m in matches:
print(f'{m.strip()}')
CodePudding user response:
import re
with open("file.txt","r") as f:
data =f.readlines()
string="".join(data)
lst=re.split(r"^This contents information\n",string)
for i in range(len(lst)):
print(lst(i).strip(),end="\n")