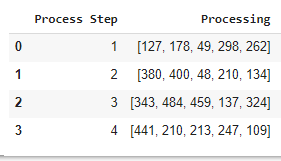
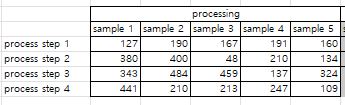
I have created a numpy array with the np.shape(sample_size, ), then I used pandas dataframe to display the data. I would like to ask you, how could I add subcolumn index for the list, for example: sample 1, sample 2, sample 3, etc ?
low = 0
high = 500
sample_size = 5
def get_numbers(low, high, sample_size):
return random.sample(range(low, high), sample_size)
p_one = np.array(get_numbers(low, high, sample_size), dtype = int)
p_two = np.array(get_numbers(low, high, sample_size), dtype = int)
p_three = np.array(get_numbers(low, high, sample_size), dtype = int)
p_four = np.array(get_numbers(low, high, sample_size), dtype = int)
p_five = np.array(get_numbers(low, high, sample_size), dtype = int)
for idn in range(0,n): #------------------n 1 for the last process step
p = [p_one, p_two, p_three, p_four, p_five]
df_rawdata = pd.DataFrame(list(zip(p)),columns =['Processing'])
CodePudding user response:
Example
we need minimal and reproducible example by code
df = pd.DataFrame([[[1, 2, 3]], [[4, 5, 6]]], index=['step1', 'step2'], columns=['process'])
df
process
step1 [1, 2, 3]
step2 [4, 5, 6]
Code
first. expand list to columns
df1 = df['process'].apply(pd.Series).rename(columns=lambda x: f'sp {x 1}')
df1
sp 1 sp 2 sp 3
step1 1 2 3
step2 4 5 6
second. make multi index
out = pd.concat([df1], keys=['process'], axis=1)
out
process
sp 1 sp 2 sp 3
step1 1 2 3
step2 4 5 6
Update
or use folowing example code:
df = pd.DataFrame([[[1, 2], [3, 4]], [[5, 6], [7, 8]]], index=['step1', 'step2'], columns=['process1', 'process2'])
df
process1 process2
step1 [1, 2] [3, 4]
step2 [5, 6] [7, 8]
out = (df.stack()
.apply(pd.Series).rename(columns=lambda x: f'sp {x 1}')
.unstack().swaplevel(0, 1, axis=1).sort_index(axis=1))
out
process1 process2
sp 1 sp 2 sp 1 sp 2
step1 1 2 3 4
step2 5 6 7 8