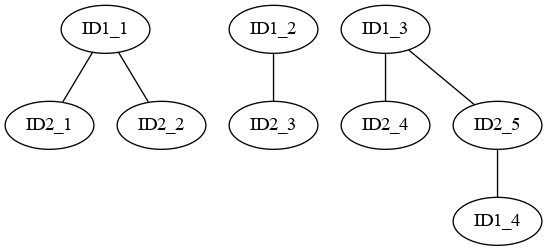
I have a table with two ID columns, I want to create a new ID that groups where these overlap.
The point of this is to understand what level you can sum the unique values linked to each id such that one total can be divided by the other, such that all value are covered and there is no double counting.
For example if there is a table like this:
| ID 1 | ID 2 |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 3 | 5 |
| 4 | 5 |
I want to create a new id column like such:
| ID 1 | ID 2 | ID 3 |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 2 | 1 |
| 2 | 3 | 2 |
| 3 | 4 | 3 |
| 3 | 5 | 3 |
| 4 | 5 | 3 |
Thanks for any help and hopefully that is clear :)
I am very new to pandas and not sure where to begin
Thanks
CodePudding user response:
This is inherently a graph problem, you can solve it robustly with