Hi I'm very new to using Big Query and SQL and I'd like to use a case when statement in Big Query to create a new column. But I need to specify the selected value based on another column. So for example:
case when Y in (
select Y
from TABLE
group by Y
having count(distinct X) > 1)
then X (where Z is max) end as new_column_value
Table Example:
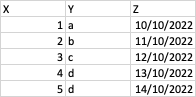
So in this example I want to identify rows where there is more than one X associated with a repeated Y value and then create a new column (shown below) where I choose one of the two ids based on the latest date. So the resulting column would be:
Example Output:
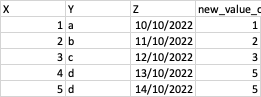
The where z is max section is where I get confused. I don't know how to put a "WHERE" clause logic, and I'm not familiar with any other alternatives to place into a "CASE" statement, in order to isolate specific values. Can someone please help me to figure this out?
CodePudding user response:
You will need to use the 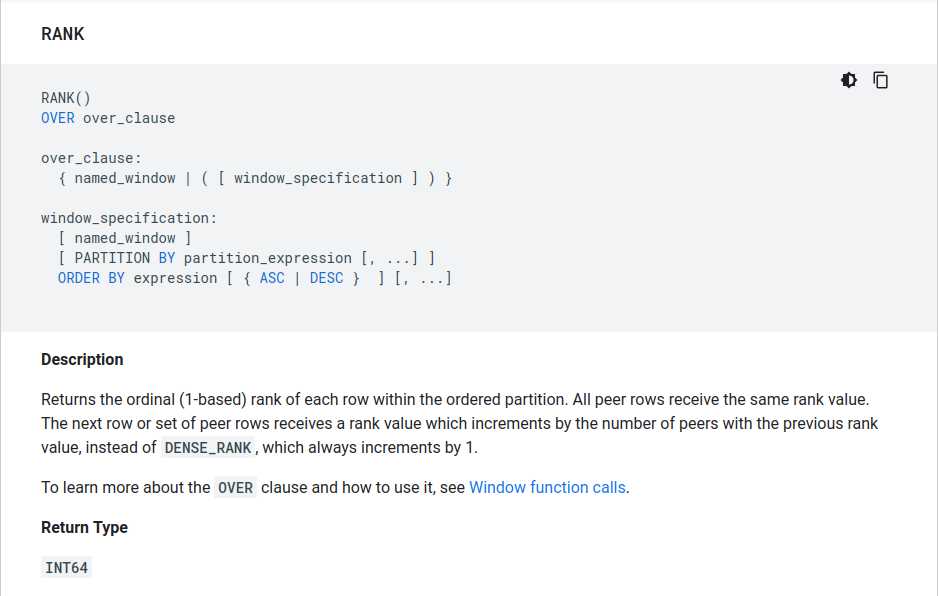
Example excerpt from the docs:
RANK() OVER (PARTITION BY division ORDER BY finish_time ASC) AS finish_rank
Basically you will need to RANK over partition. I would advise you to use a JOIN between your main query and subquery, grouping by Y, instead of using a case-when in the select clause and then add this to your select
RANK() OVER (PARTITION BY X ORDER BY Y ASC) AS new_column_value
CodePudding user response:
Use FIRST_VALUE() window function:
SELECT X, Y, Z,
FIRST_VALUE(X) OVER (PARTITION BY Y ORDER BY Z DESC) AS new_column_value
FROM tablename;