Table 1:
ID | Type1 | Type2 | CoId |
101 | 13 | 9 | 920 |
102 | 14 | 9 | 012 |
103 | 0 | 14 | 130 |
150 | 0 | 15 | 520 |
153 | 13 | 6 | 160 |
160 | 7 | 13 | 170 |
170 | 5 | 13 | 200 |
200 | 4 | 13 | 0 |
920 | 0 | 13 | 150 |
Table2 :
ID | Value
101 | 'abc'
102 | 'bcd'
103 | 'cde'
150 | 'def'
153 | 'efg'
160 | 'fgh'
170 | 'ghi'
200 | 'hij'
920 | 'ijk'
Table3:
ID | Position
101 | 1
102 | 19
103 | 10
150 | 90
153 | 12
160 | 2
170 | 7
200 | 3
920 | 6
I need to create a final table which would have ID and final CoId value mapped with each other. The problem is the CoId can have another CoID and so on and I need to find the final CoId.
Also we need to map only those Id's whose Type1 = '13' and the valid CoId's are only those whose Type2 = '13' or whose CoId is not 0
The result table should look like:
Final Table
Id | Final CoId | Value
101 | 150 | 'def'
102 | null | null
103 | null | null
...
153 | 200 | 'hij'
Logic: Case 1
101 -> Type1 = 13, Condition Satisfied, We find the value for this Id
101's CoId = 920
920 -> Type2 = 13, Condition Satisfied, We keep searching for CoId
920's CoId = 150
150 -> Type2 = 13, Condition Not Satisfied, We finish the search here and take 150 as CoId and take the value of 150 from Table2
Case 2
102 -> Type1 = 13, Condition not Satisfied, We don't find Value for this Id
Similarly for 103,150,160,170,200,920
Case 3
153 -> Type1 = 13, Condition Satisfied, We find the final CoId for 153
153's CoId = 160
160 -> Type2 = 13, Condition Satisfied, We keep searching for CoId
160's CoId = 170
170 -> Type2 = 13, Condition Satisfied, We keep searching for CoId
170's CoId = 200
200 -> Type = 13, 1st Condition Satisfied but 2nd Condition not satisfied where CoId should not be '0', We stop searching for CoId
Final CoId = 200
My Solution
Select a.ID, D.Id, D.value from
Table3 AS a LEFT JOIN Table1 AS b
On a.Id = b.id
AND b.Type1 = '13'
INNER JOIN Table1 As C
On b.CoId = C.id
AND c.Type2 = '13' --- Need to recursively join this one until the condition fails
AND c.CoId <> 0
INNER Join Table2 As D
On C.ObId = D.ID
This Solution's output
Id | Final CoId | Value
101 | 150 | 'def'
102 | null | null
103 | null | null
...
153 | null | null
This above solution works for Case 1, as I have hardcoded it to stop after 1 join. How can I make that Type2 = '13' join run multiple times dynamically till the condition is satisfied and then pass the CoId to the third join where I join with Table2 like in case 3.
Note: If Type1 = 13 Condition for an ID is satisfied, then the CoId must have at-least one Type2 = 13 relation, so the join were we match Type2 = 13 will always succeed at least once if the first condition of Type1 = 13 is met.
Any idea how this can be achieved?
CodePudding user response:
The problem with Spark is that it does not support recursive Common Table Expressions. When I think of Hierarchies, I think of a SQL database and recursive CTE. But don't fret, it can be solved.
I will be doing this coding in Azure Databricks. We need 3 sample data frames that contain your sample data.
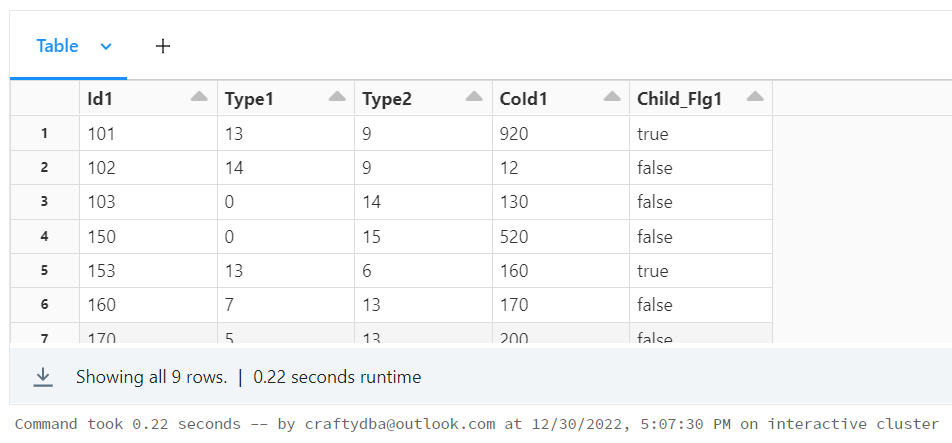
Code snippet 1
#
# 1 - Create sample dataframe view
#
# array of tuples - data
dat1 = [
(101,13,9,920),
(102,14,9,12),
(103,0,14,130),
(150,0,15,520),
(153,13,6,160),
(160,7,13,170),
(170,5,13,200),
(200,4,13,0),
(920,0,13,150)
]
# array of names - columns
col1 = ["Id1", "Type1", "Type2", "CoId1"]
# make data frame
df1 = spark.createDataFrame(data=dat1, schema=col1)
# make temp hive view
df1.createOrReplaceTempView("tmp_table1")
# show schema
df1.printSchema()
# show data
display(df1)
Code Snippet 2
#
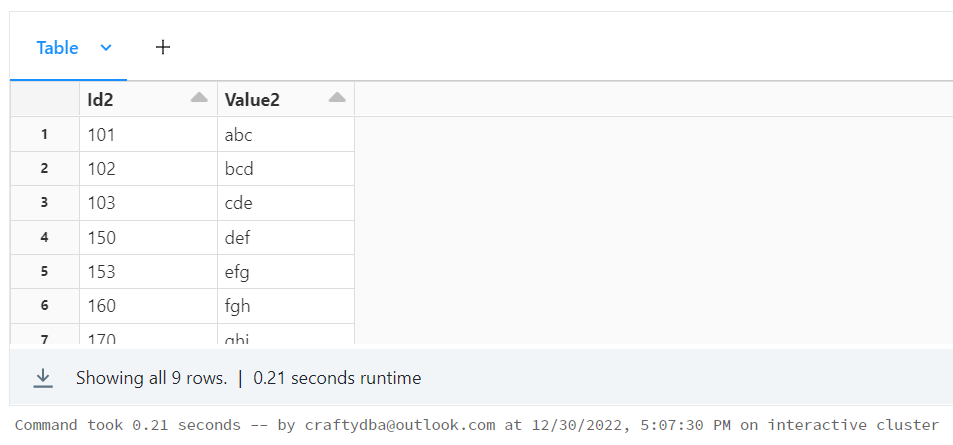
# 2 - Create sample dataframe view
#
# array of tuples - data
dat2 = [
(101,'abc'),
(102,'bcd'),
(103,'cde'),
(150,'def'),
(153,'efg'),
(160,'fgh'),
(170,'ghi'),
(200,'hij'),
(920,'ijk')
]
# array of names - columns
col2= ["Id2", "Value2"]
# make data frame
df2 = spark.createDataFrame(data=dat2, schema=col2)
# make temp hive view
df2.createOrReplaceTempView("tmp_table2")
# show schema
df2.printSchema()
# show data
display(df2)
Code Snippet 3
#
# 3 - Create sample dataframe view
#
# array of tuples - data
dat3 = [
(101,1),
(102,19),
(103,10),
(150,90),
(153,12),
(160,2),
(170,7),
(200,3),
(920,6)
]
# array of names - columns
col3 = ["Id3", "Position3"]
# make data frame
df3 = spark.createDataFrame(data=dat3, schema=col3)
# make temp hive view
df3.createOrReplaceTempView("tmp_table3")
# show schema
df3.printSchema()
# show data
display(df3)
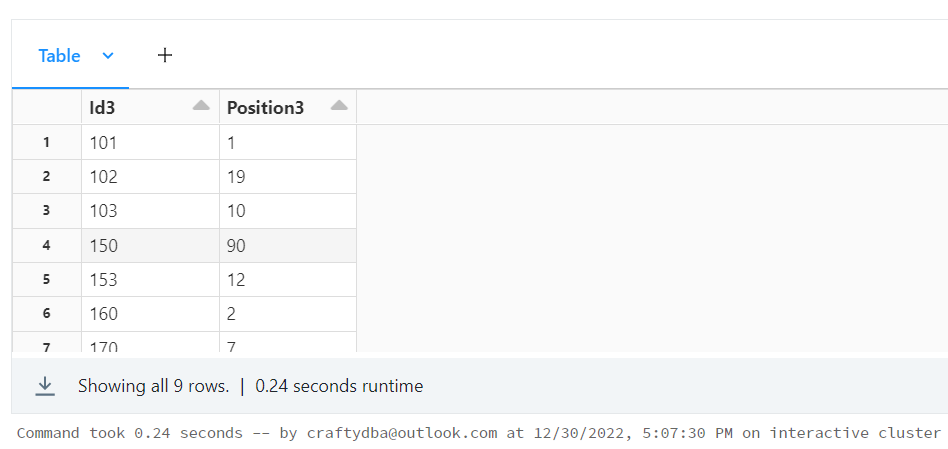
At this point, I usually solve the problem with Spark SQL. But we can not do that here. Also, the third data frame is never used in the solution. Something I want to point out.
Now we will write a recursive function to get the id trail.
#
# get_id_trail() - define function to get id trail
#
def get_id_trail(id_str):
# create dynamic query
stmt = """
select
a.Id1,
a.CoId1,
a.Type1,
b.CoId1 as CoId2,
b.Type2,
case
when (b.CoId1 is null or a.Type1 <> 13 or b.Type2 <> 13) then 1
else 0
end as StopFlg
from (select * from tmp_table1 where Id1 in ({})) a
left join tmp_table1 b
on b.Id1 = a.CoId1
"""
stmt = stmt.format(id_str)
# create data frame
tmp = spark.sql(stmt)
# exit condition
if (tmp.first().StopFlg == 1):
ret = []
ret.append(tmp.first().Id1)
ret.append(-1)
return(ret)
# continue condition
else:
ret = []
ret.append(tmp.first().Id1)
ret.append(tmp.first().CoId1)
ret = ret get_id_trail(tmp.first().CoId2)
return(ret)
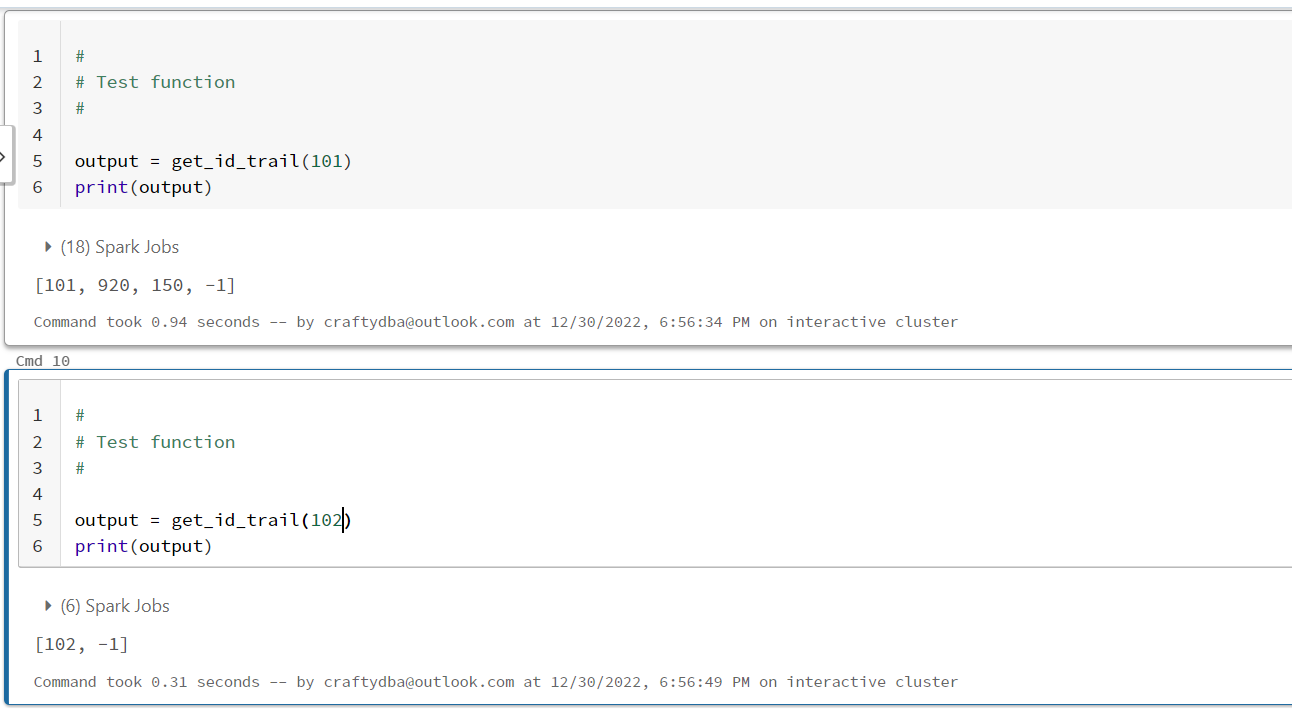
When you do recursion, you have to be careful that the data does not have circles! Otherwise, you will have an infinite loop. The stop recursion case results in marking the final id as -1 for that case. Thus, there a no value matches.
The image below show valid results for two use cases.
Again, I can not use a technique that I love. Create a user defined function that can be used with Spark SQL. The issue is the to use Spark SQL, we have a spark session already.
We must result to forcing the dataframe into a simple loop, pick out columns, make the function call, add to an growing list and convert the result into a dataframe.
The code below does just that.
#
# 4 - Create output df
#
# array of names - columns
col4 = ["StartId", "FinalId"]
# empty list
dat4 = []
# for each row of data
for row1 in df1.collect():
# get id trail
ids = get_id_trail(row1["Id1"])
# if size = 2 then -1 else -1 for final id
if (len(ids) == 2):
tup = (ids[0], ids[-1])
else:
tup = (ids[0], ids[-2])
# add to list
dat4.append(tup)
# make data frame
df4 = spark.createDataFrame(data=dat4, schema=col4)
# make temp hive view
df4.createOrReplaceTempView("tmp_table4")
There is really not output as per a print statement. However, if we join temp table 4 and 2, we will get the answer. I can finally use SPARK SQL!
%sql
select a.*, b.Value2 as FinalVal
from tmp_table4 as a
left join tmp_table2 as b
on a.FinalId = b.Id2
order by FinalVal Desc
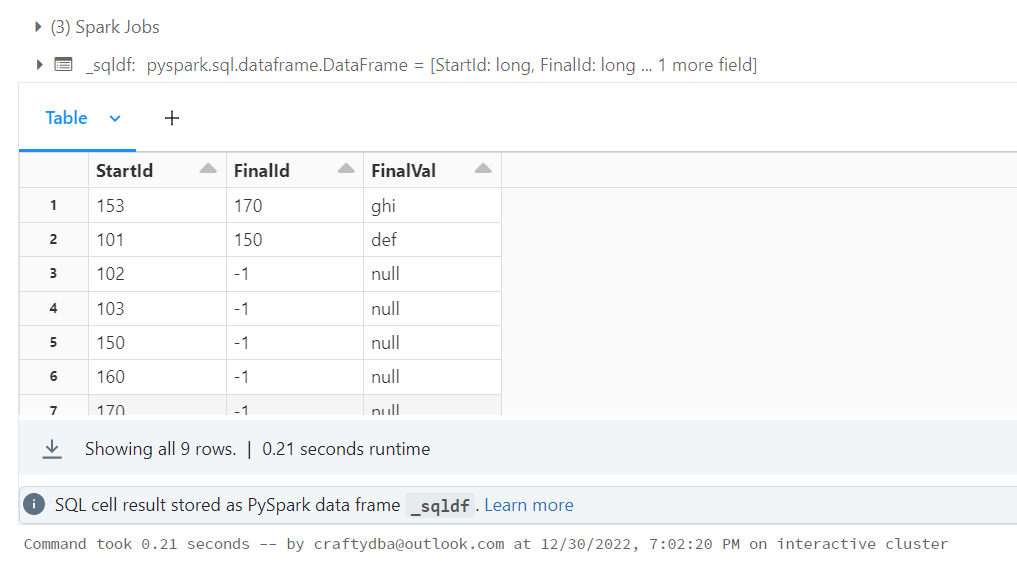
The correct answer is shown above. One of the things that I think about when writing spark code is performance. Will this code scale well? Probably not. Spark is not really good at recursion. Also, the collect() function forces everything to the executor node.
If I am bored later, I might repost an answer using the graph api that is part of spark. That might execute better for large scale data sets since it is built for nodes and traversals.
Please up tick since this is a good solution.