I'm pretty new to Python/Pandas with a majority of my experience being in SQL/SAS. Unfortunately i'm using an old version of Jupyter notebook which doesn't allow me to install the sql package at work.. well without luck currently.
I'm facing the following dataset and trying to do a if-then condition in-conjunction with a group by statement to sum up the groups product limit by HL and Other.
In my SQL mind i would usually do it as if product = 'HL' then limit as HL_LIMIT else limit = BL_LIMIT.
I'm facing great difficulty doing this in Pandas as i'm still relatively new to the language. Hoping someone can guide my on how to complete this problem.
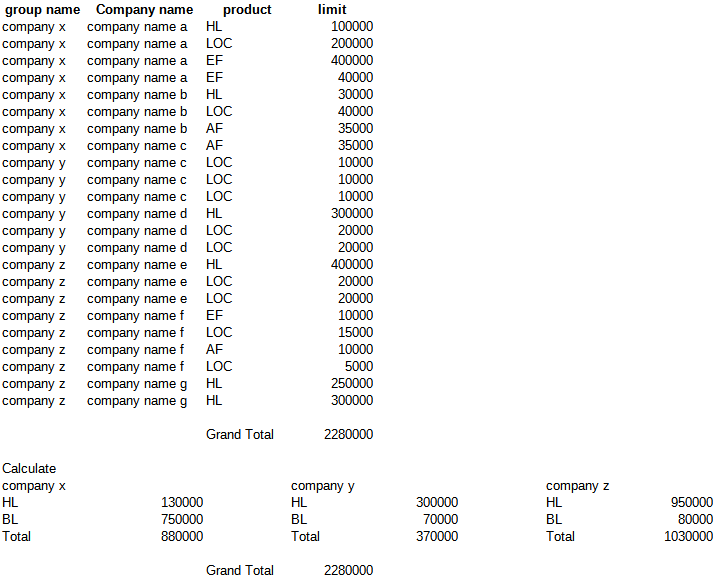
The dummy dataset shows my excel manual calculation that i am expecting but trying to code.
I've been trying to do a for loop statement through 'group name' with a if then statement to create new fields of the HL_LIMIT / BL_LIMIT before completing it with some additional calculations required.
CodePudding user response:
import numpy as np
df['limit'] = np.where(df['group name'] == 'HL', df['HL_LIMIT'], df['BL_LIMIT'])
CodePudding user response:
If you want output in de-normalized dataframe form, then use following. The logic is explained as comment above each line.
# Categorize values as "HL" and "BL".
df["product"] = df["product"].apply(lambda p: p if p == "HL" else "BL")
# Compute total for each group and product.
df = df.groupby(["group name", "product"]).sum("limit").reset_index()
# Compute total for each group.
df_total = df.groupby("group name").sum("limit").reset_index()
df_total["product"] = "Total"
df = pd.concat([df, df_total]).reset_index(drop=True)
# Transform by group
df = df.pivot(index="product", columns="group name", values="limit").rename_axis("", axis="columns").reset_index()
Output:
product company x company y company z
0 BL 750000 70000 80000
1 HL 130000 300000 950000
2 Total 880000 370000 1030000
If you want output extactly like your excel, then you need to do some cosmetic transformations:
# Categorize values as "HL" and "BL".
df["product"] = df["product"].apply(lambda p: p if p == "HL" else "BL")
# Compute total for each group and product.
df = df.groupby(["group name", "product"]).sum("limit").reset_index()
# Compute total for each group.
df_total = df.groupby("group name").sum("limit").reset_index()
df_total["product"] = "Total"
df = pd.concat([df, df_total]).reset_index(drop=True)
# Stack each group's block horizontally.
dfs = []
for g in df["group name"].unique():
df_g = df[df["group name"] == g].drop("group name", axis=1).reset_index(drop=True)
df_g.columns = [g, ""]
dfs.append(df_g)
df = pd.concat(dfs, axis=1)
Output:
company x company y company z
0 BL 750000 BL 70000 BL 80000
1 HL 130000 HL 300000 HL 950000
2 Total 880000 Total 370000 Total 1030000