I have a table of data in which companies have differing numbers of locations with different values for each key.
| Key | Company | Value | Location |
|---|---|---|---|
| Start | Burgers | Monday | Sydney |
| Start | Burgers | Sunday | Brisbane |
| Start | Donuts | Monday | Sydney |
I want to count the different values but normalised so that companies with multiple locations don't skew things. The output i'm hoping for is something like this:
| Value | Count |
|---|---|
| Monday | 1.5 |
| Sunday | 0.5 |
Keep banging my head against how to approach this so any help is greatly appreciated.
CodePudding user response:
I think you're looking for something like this:
df1 = df.groupby(['Key', 'Value', 'Company'], as_index=False).agg({'Location': 'count'})
df1['Total Locations'] = df1.groupby(['Key', 'Company'], as_index=False)['Location'].transform(lambda grp: grp.sum())
df1['Location Rate'] = df1['Location'] / df1['Total Locations']
final_df = df1.groupby(['Key', 'Value'], as_index=False).agg({'Location Rate': 'sum'})
final_df
Output:
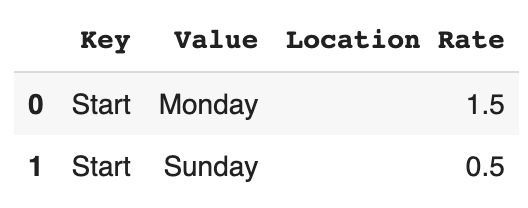
Full Example
Here's the full example, including imports, the example data that you included on your question, and some comments about what each step is doing:
# == Necessary Imports ==================================================
import pandas as pd
# == Example Data =======================================================
df = pd.DataFrame(
[['Start','Burgers','Monday','Sydney'],
['Start','Burgers','Sunday','Brisbane'],
['Start','Donuts','Monday','Sydney']],
columns=['Key', 'Company', 'Value', 'Location'],
)
# == Solution ===========================================================
# 1. Count the number of "Locations" that each set of ['Key', 'Value', 'Company'] has.
df1 = df.groupby(['Key', 'Value', 'Company'], as_index=False).agg({'Location': 'count'})
# df1:
# Key Value Company Location
# 0 Start Monday Burgers 1
# 1 Start Monday Donuts 1
# 2 Start Sunday Burgers 1
# 2. Using the `.transform` method, count the total number
# of Locations that each set of ['Key', 'Company'] has
df1['Total Locations'] = df1.groupby(['Key', 'Company'], as_index=False)['Location'].transform(lambda grp: grp.sum())
# df1:
# Key Value Company Location Total Locations
# 0 Start Monday Burgers 1 2
# 1 Start Monday Donuts 1 1
# 2 Start Sunday Burgers 1 2
# 3. Divide the Location count by the total number of locations
# previously obtained.
df1['Location Rate'] = df1['Location'] / df1['Total Locations']
# df1:
# Key Value Company Location Total Locations Location Rate
# 0 Start Monday Burgers 1 2 0.5
# 1 Start Monday Donuts 1 1 1.0
# 2 Start Sunday Burgers 1 2 0.5
# 4. Group by each set of 'Key' and 'Value' and sum all the 'Location Rate'
# values obtained from the previous step
final_df = df1.groupby(['Key', 'Value'], as_index=False).agg({'Location Rate': 'sum'})
# df_final:
# Key Value Location Rate
# 0 Start Monday 1.5
# 1 Start Sunday 0.5
Solution Using Method Chains
If you don't want to create intermediary pandas Data Frames, like df1, you can combine all the steps into a single chain of commands, like so:
final_df = (
df
.groupby(['Key', 'Value', 'Company'], as_index=False)
.agg({'Location': 'count'})
.assign(
Total_Locations=lambda xdf: xdf.groupby(['Key', 'Company'], as_index=False)['Location']
.transform(lambda grp: grp.sum())
)
.assign(Location_Rate=lambda xdf: xdf['Location'] / xdf['Total_Locations'])
.groupby(['Key', 'Value'], as_index=False).agg({'Location_Rate': 'sum'})
)
Note: long method chains make your code harder to debug, and for others to understand what you're trying to achieve.
Note 2: the method pandas.DataFrame.assign allows you to reference columns from a previous step from the chain. For example, the second .assign references the Total_Locations, when creating the Location_Rate column.