In Pyspark, I want to combine concat_ws and coalesce whilst using the list method. For example I know this works:
from pyspark.sql.functions import concat_ws, col
df = spark.createDataFrame([["A", "B"], ["C", None], [None, "D"]]).toDF("Type", "Segment")
#display(df)
df = df.withColumn("concat_ws2", concat_ws(':', coalesce('Type', lit("")), coalesce('Segment', lit(""))))
display(df)

But I want to be able to utilise the *[list] method so I don't have to list out all the columns within that bit of code, i.e. something like this instead:
from pyspark.sql.functions import concat_ws, col
df = spark.createDataFrame([["A", "B"], ["C", None], [None, "D"]]).toDF("Type", "Segment")
list = ["Type", "Segment"]
df = df.withColumn("almost_desired_output", concat_ws(':', *list))
display(df)
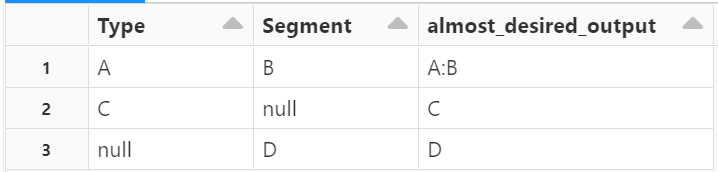
However as you can see, I want to be able to coalesce NULL with a blank, but not sure if that's possible using the *[list] method or do I really have to list out all the columns?
CodePudding user response:
This would work:
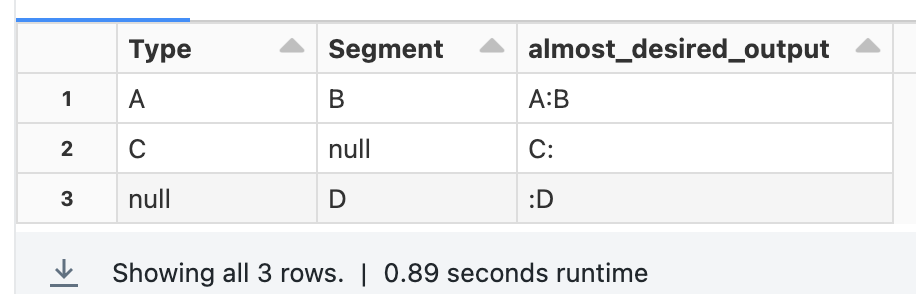
Iterate over list of columns names
df=df.withColumn("almost_desired_output", concat_ws(':', *[coalesce(name, lit('')).alias(name) for name in df.schema.names]))
Output:
Or, Use fill - it'll fill all the null values across all columns of Dataframe (but this changes in the actual column, which may can break some use-cases)
df.na.fill("").withColumn("almost_desired_output", concat_ws(':', *list)
Or, Use selectExpr (again this changes in the actual column, which may can break some use-cases)
list = ["Type", "Segment"] # or just use df.schema.names
list2 = ["coalesce(type,' ') as Type", "coalesce(Segment,' ') as Segment"]
df=df.selectExpr(list2).withColumn("almost_desired_output", concat_ws(':', *list))