I have a data frame in R that looks like this:
structure(list(items = c("Apple", "Apple, Pear", "Apple, Pear, Banana"
)), row.names = c(NA, -3L), class = "data.frame")
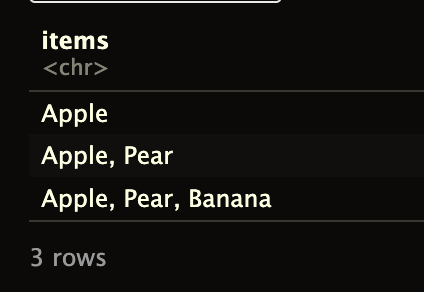
I would like to create new columns for each item in the "items" column and count the frequency of each item. For example, I want to create an "Apple" column that contains the frequency of "Apple" in the "items" column, a "Pear" column that contains the frequency of "Pear" in the "items" column, and so on.
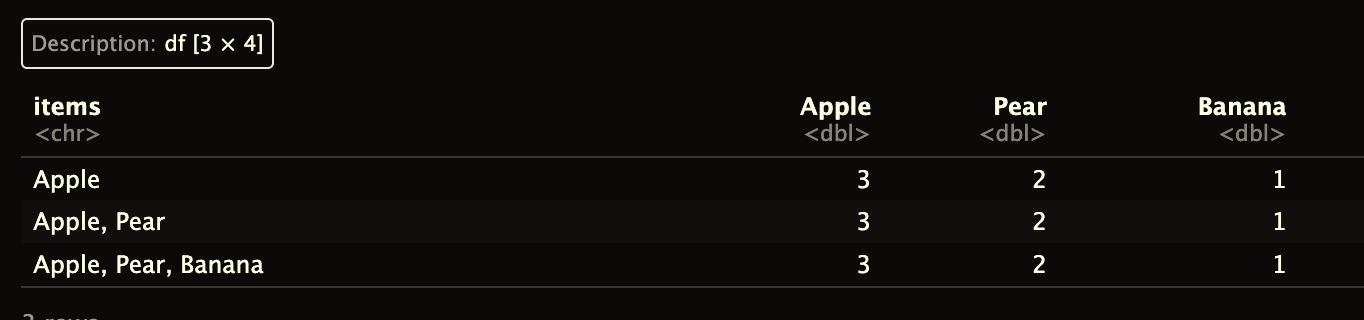
The final data frame should look like this:
structure(list(items = c("Apple", "Apple, Pear", "Apple, Pear, Banana"
), Apple = c(3, 3, 3), Pear = c(2, 2, 2), Banana = c(1, 1, 1)), row.names = c(NA,
-3L), class = "data.frame")
I have tried using the mutate() and str_count() functions from the dplyr and stringr packages, but I'm not sure how to get the final data frame that I want.
Here is the code that I have tried so far:
items %>%
mutate(Apple = str_count(items, "Apple"),
Pear = str_count(items, "Pear"),
Banana = str_count(items, "Banana"))
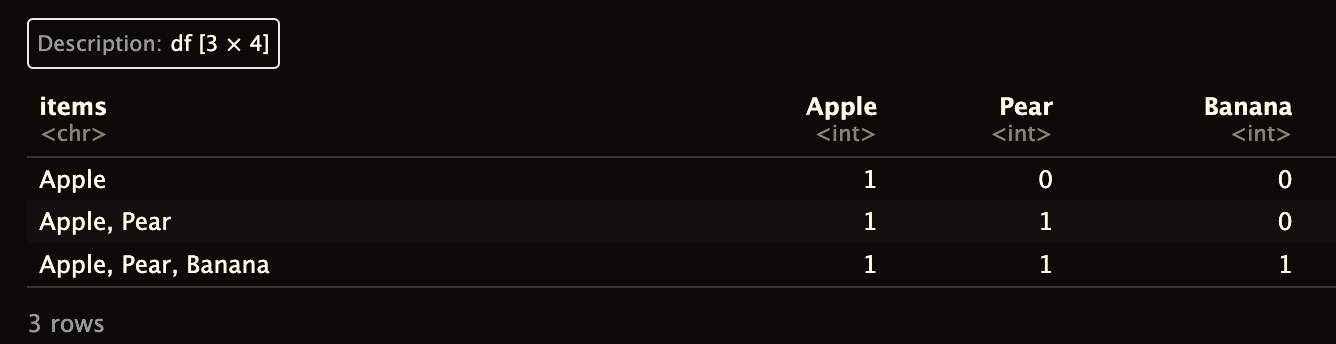
This gets me part way there, but I'm not sure how to create a new column for each item and count the frequency of each item. Can someone help me figure out how to do this in R?
CodePudding user response:
You can wrap str_count with sum:
items %>%
mutate(Apple = sum(str_count(items, "Apple")),
Pear = sum(str_count(items, "Pear")),
Banana = sum(str_count(items, "Banana")))
items Apple Pear Banana
1 Apple 3 2 1
2 Apple, Pear 3 2 1
3 Apple, Pear, Banana 3 2 1
CodePudding user response:
Especially in situation where you have multiple rows and values ->
Here is a solution using separate the rows count and combining with cbind and finally pivoting with filling the NAs:
library(dplyr)
library(tidyr)
df %>%
separate_rows(items, sep='\\,') %>%
count(items1 = trimws(items)) %>%
cbind(df) %>%
pivot_wider(names_from = items1, values_from = n) %>%
fill(-items, .direction = "downup")
items Apple Banana Pear
<chr> <int> <int> <int>
1 Apple 3 1 2
2 Apple, Pear 3 1 2
3 Apple, Pear, Banana 3 1 2
CodePudding user response:
Using map - loop over the words of interest, and transmute to return a single column with the count of the word in the items column and bind the output to the original data
library(purrr)
library(dplyr)
map_dfc(c("Apple", "Pear", "Banana"), ~ df1 %>%
transmute(!! .x := sum(str_count(items, .x)))) %>%
bind_cols(df1, .)
-output
items Apple Pear Banana
1 Apple 3 2 1
2 Apple, Pear 3 2 1
3 Apple, Pear, Banana 3 2 1
Or another option is to split the column 'items', use mtabulate and cbind the columns after getting the colSums
library(qdapTools)
cbind(df1, as.list(colSums(mtabulate(strsplit(df1$items, ",\\s*")))))
items Apple Banana Pear
1 Apple 3 1 2
2 Apple, Pear 3 1 2
3 Apple, Pear, Banana 3 1 2
CodePudding user response:
You can try the following,
library(tidyverse)
df <- structure(list(items = c(
"Apple", "Apple, Pear", "Apple, Pear, Banana"
)),
row.names = c(NA,-3L),
class = "data.frame")
total_count <- function(x, word) {
paste0(x, collapse = ", ") %>%
stringr::str_count(word)
}
df %>%
mutate(Apple = total_count(items, "Apple"),
Pear = total_count(items, "Pear"),
Banana = total_count(items, "Banana"))
#> items Apple Pear Banana
#> 1 Apple 3 2 1
#> 2 Apple, Pear 3 2 1
#> 3 Apple, Pear, Banana 3 2 1
Created on 2023-01-04 with reprex v2.0.2