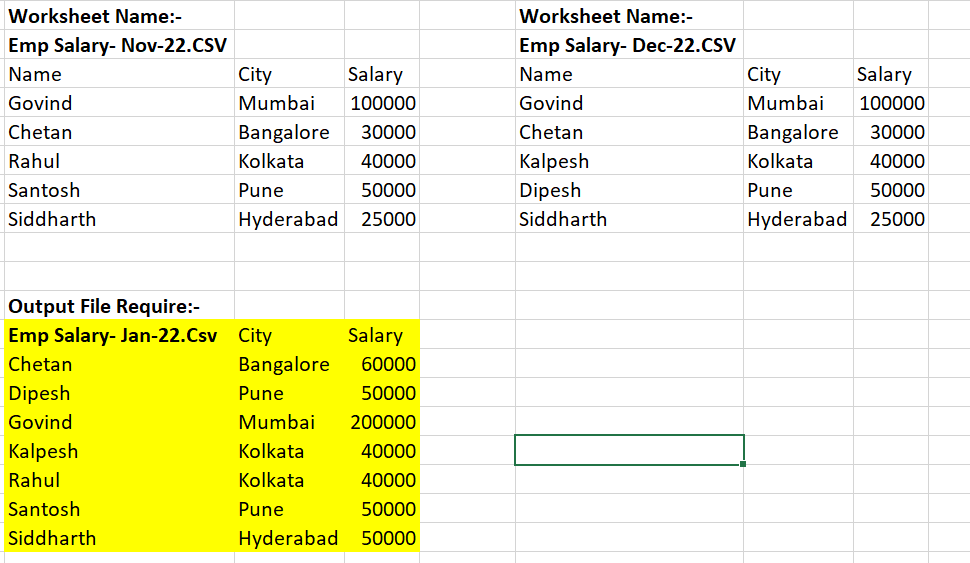
Could you please help me to get output for considering two worksheets (Emp Salary- Nov-22.CSV / Emp Salary- Dec-22.CSV). I want to get each column's unique name value in new output file.
CodePudding user response:
Welcome to stackoverflow, you are required to post whatever work you have done so far to tackle the problem.
To answer your question, this can be done is excel with pivot tables. But if you are looking for a pandas method... I have created 2 dataframes like you have
import pandas as pd
import numpy as np
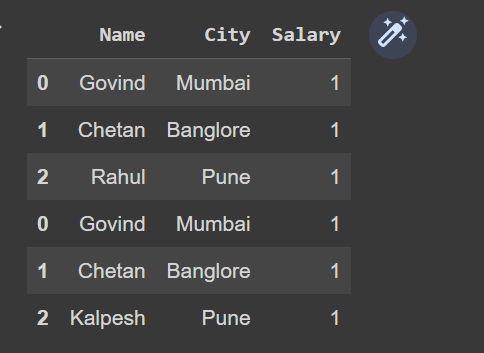
df1 = pd.DataFrame(
{ "Name": ['Govind', 'Chetan', 'Rahul'],
"City": ['Mumbai', 'Banglore', 'Pune'],
"Salary": [1, 1, 1] })
df2 = pd.DataFrame(
{ "Name": ['Govind', 'Chetan', 'Kalpesh'],
"City": ['Mumbai', 'Banglore', 'Pune'],
"Salary": [1, 1, 1] })
You can then use concat to concatenate them
df = pd.concat([df1, df2], axis=0)
df
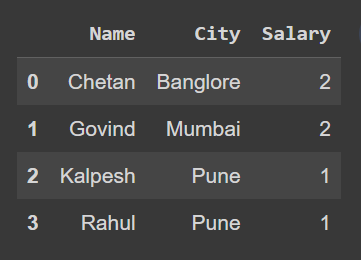
and you can use groupby() and reset_index() to get what you want
df.groupby(['Name','City'])['Salary'].sum().reset_index()
CodePudding user response:
You can use pandas.read_excel with sheet_name=None to read all the sheets at once and then pass the dictionnary of dataframes made to pandas.concat and finally use Groupby.sum for aggregation :
import pandas as pd
out = (
pd.concat(pd.read_excel("/input_spreadsheet.xlsx", sheet_name=None), ignore_index=True)
.groupby(["Name", "City"], as_index=False)["Salary"].sum()
)
After that, if needed, you can make an new spreadsheet with pandas.DataFrame.to_excel and/or a (.csv) file with pandas.DataFrame.to_csv :
out.to_excel("/output_spreadsheet.xlsx", sheet_name="Emp Salary (Total).xlsx", index=False)
out.to_csv("/output_csvfile.csv", sheet_name="Emp Salary (Total).csv", sep=",", index=False) #sep="," by default
# Output :
print(out)
Name City Salary
0 Chetan Bangalore 60000
1 Dipesh Pune 50000
2 Govind Mumbai 200000
3 Kalpesh Kolkata 40000
4 Rahul Kolkata 40000
5 Santosh Pune 50000
6 Siddharth Hyderabad 50000