I would like to turn a table into a pandas.DataFrame.
URL = 'https://ladieseuropeantour.com/reports-page/?tourn=1202&tclass=rnk&report=tmscores~season=2015~params=P*4ESC04~#/profile'
The element in question is
from selenium import webdriver
from selenium.webdriver.common.by import By
driver.get(URL)
ranking = driver.find_element(By.XPATH, ".//*[@id='maintablelive']")
I tried the following:
import pandas as pd
pd.read_html(ranking.get_attribute('outerHTML'))[0]
I am also using the dropdown-menu to select multiple rounds. When a different round is selected, driver.current_url doesn't change so I think it's not possible to load these new tables with requests or anything.
Please advice!
CodePudding user response:
Instead of using selenium, you want to access the URL's API endpoint.
Finding the API endpoint
You can trace it as follows:
- Open the URL in Chrome
- Use
Ctrl Shift Jto open DevTools, navigate toNetwork, selectFetch/XHRfrom the sub navbar, and refresh the URL. - This will reload the network connections, and when you click on one of the lines that will appear, you can select
Responsefrom the second sub navbar to see if they are returning data. - Going through them, we can locate the connection that is responsible for returning the data for the table, namely
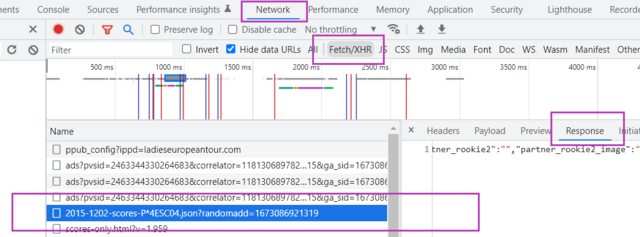
Now, with this knowledge, we can simply load all the data with
requests, investigate the type of information that is contained in theJSONand dump the required sub part in adf.For example, let's recreate the table from your URL. This one:
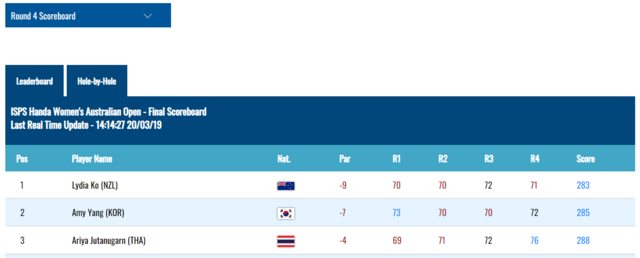
Code
import requests import pandas as pd url = 'https://ladieseuropeantour.com/api/let/cache/let/2015/2015-1202-scores-P*4ESC04.json' data = requests.get(url).json() df = pd.DataFrame(data['scores']['scores_entry']) cols = ['pos','name','nationality','vspar', 'score_R1','score_R2','score_R3','score_R4', 'score'] df_table = df.loc[:,cols] df_table.head() pos name nationality vspar score_R1 score_R2 score_R3 \ 0 1 Lydia Ko (NZL) NZL -9 70 70 72 1 2 Amy Yang (KOR) KOR -7 73 70 70 2 3 Ariya Jutanugarn (THA) THA -4 69 71 72 3 4 Jenny Shin (KOR) KOR -2 76 71 74 4 4 Ilhee Lee (KOR) KOR -2 68 82 69 score_R4 score 0 71 283 1 72 285 2 76 288 3 69 290 4 71 290If you check
print(df.columns), you'll see that the maindfcontains all the data that lies behind all of the tables you can select on the URL. So, have a go at that to select whatever you are looking for.