We've been looking at memory for capacity planning and have a Helm-deployed 8GB-limited QuestDB instance running on one of our k8s clusters.
We recently began scraping metrics off of it. I'm trying to get to the bottom of the questdb_memory_mem_used metric, which occasionally sees excursions way beyond the resource limits.
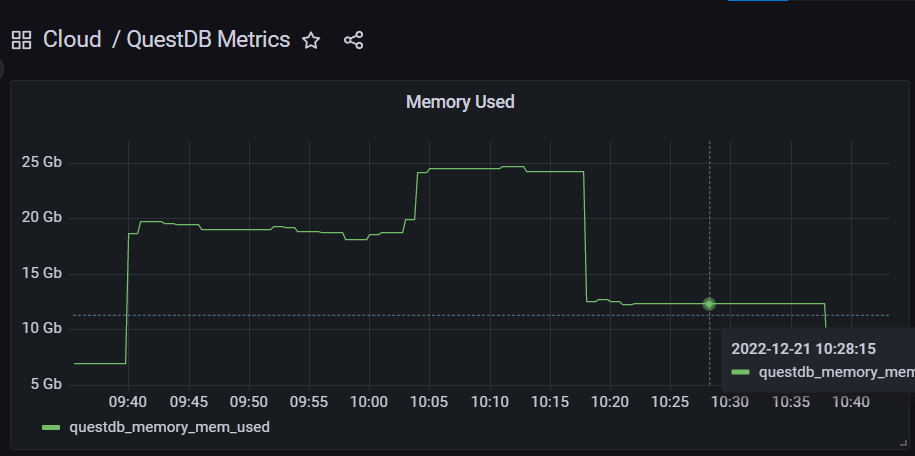
Does anyone have a good handle on what contributes to this metric and what we could be seeing?
For reference the NATIVE_* tagged metrics seem much more sane in the same time period:
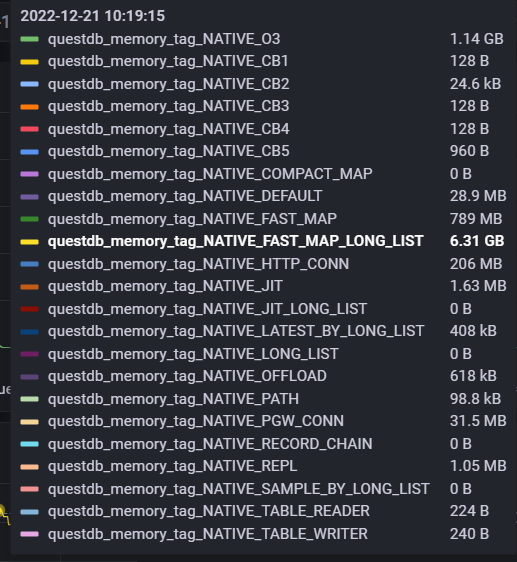
CodePudding user response:
According to the documented Prometheus metrics exposed by QuestDB, questdb_memory_mem_used includes all native memory allocations which may include virtual memory if it wasn't touched yet.
This metric includes mmapped files, so that's why its value is that big. You might see that metric grow when you access large tables on your instance. DISTINCT and JOIN queries will also affect this metric.
Please note mmapped memory is elastic and mostly virtual. Only free memory is used for the page cache, so it's fine if this metric has a large value.