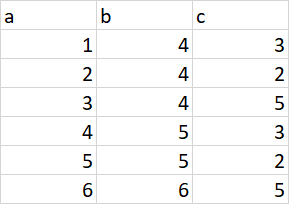
I have a dataframe like this:
Reproduce:
df = spark.createDataFrame([(1, 4, 3), (2, 4, 2), (3, 4, 5), (1, 5, 3), (2, 5, 2), (3, 6, 5)], ['a', 'b', 'c'])
I want to restrict the duplicates of column 'b' to two, only two duplicates will be kept, rest will be dropped. After that, I want to add a new column as 'd', where there will be a rolling window of numeric values in Ascending order as 1,2 like:
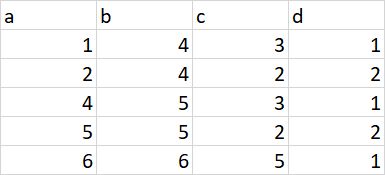
Is there anything like pandas rolling window equivalent in Pyspark which I have failed to dig out from Stack Overflow and documentation where I can do something like what I may have done on pandas:
y1 = y[df.COL3 == 'b']
y1 = y1.rolling(window).apply(lambda x: np.max(x) if len(x)>0 else 0).fillna('drop')y = y1.reindex(y.index, fill_value = 0).loc[lambda x : x!='drop']
I am new to PySpark, thanks in advance.
CodePudding user response:
You can create a Window, partition by column b, do row_numner on that window and filter the row numbers less or equal 2:
# Prepare data:
from pyspark.sql.functions import row_number
from pyspark.sql import SparkSession, Window
spark = SparkSession.builder.master("local[*]").getOrCreate()
df = spark.createDataFrame([(1, 4, 3), (2, 4, 2), (3, 4, 5), (1, 5, 3), (2, 5, 2), (3, 6, 5)], ['a', 'b', 'c'])
# Actual work
w = Window.partitionBy(col("b")).orderBy(col("b"))
df.withColumn("d", row_number().over(w)).filter(col("d") <= 2).show()
--- --- --- ---
| a| b| c| d|
--- --- --- ---
| 1| 4| 3| 1|
| 2| 4| 2| 2|
| 1| 5| 3| 1|
| 2| 5| 2| 2|
| 3| 6| 5| 1|
--- --- --- ---