I am trying to find some value drops and classify the complete drop as TRUE or FALSE. Here is some example data with visualization:
df <- data.frame(time = c(1:14),
value = c(100, 102, 102, 90, 99, 99, 96, 96, 94, 94, 96, 96, 97, 97))
library(ggplot2)
ggplot(df, aes(x = time, y = value))
geom_step()
geom_point()
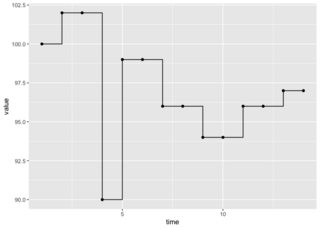
Created on 2023-01-12 with reprex v2.0.2
I would like to find the time steps (3,4,5,6) and (8,9,10,11,12) because I am trying to find values which if the difference with next value < 0 and its next difference stays the same or jumps, that should be the drop. Here is a for-loop I tried:
values <- df$value
result <- rep("FALSE", length(values))
for (i in 2:(length(values)-1)) {
if (values[i] < values[i-1] && (values[i 1] >= values[i])) {
result[i-1] <- "TRUE"
result[i] <- "TRUE"
result[i 1] <- "TRUE"
}
}
result
#> [1] "FALSE" "FALSE" "TRUE" "TRUE" "TRUE" "TRUE" "TRUE" "TRUE" "TRUE"
#> [10] "TRUE" "FALSE" "FALSE" "FALSE" "FALSE"
Created on 2023-01-12 with reprex v2.0.2
But the problem with this is that it thinks that at timestamp 7 it is a value drop, but the next value is although the same but after that drops which isn't the clean drop/jump (the U form) I am looking for.
So I was wondering if anyone knows how to find these kind of value drops/jumps in R?
CodePudding user response:
A for loop using an anchor (ilast):
v <- c(100, 102, 102, 90, 99, 99, 96, 96, 94, 94, 96, 96, 97, 97)
d <- diff(v)
out <- vector("list", length(d)%/%2)
io <- 0L
fall <- FALSE
for (i in 1:length(d)) {
if (d[i] < 0) {
ilast <- i
fall <- TRUE
} else if (d[i] > 0) {
if (fall) out[[io <- io 1L]] <- ilast:(i 2L)
ilast <- i
fall <- FALSE
}
}
out <- out[1:io]
out
#> [[1]]
#> [1] 3 4 5 6
#>
#> [[2]]
#> [1] 8 9 10 11 12