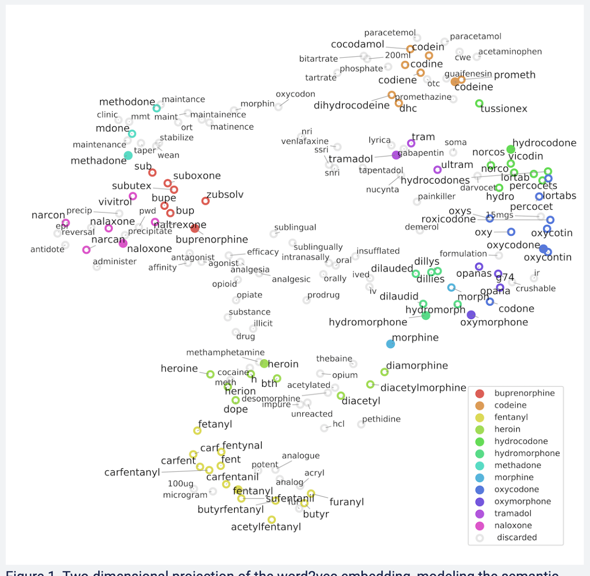
I would like to reproduce the scatterplot below. Here is the code I have so far, but I cannot seem to get the points similar to the seed terms to be the same color as the filled points (seed terms). Any help is appreciated. Also, I cannot figure out why the first word is the color white, even though I used a specific palette?
import pandas as pd
import numpy as np
import matplotlib
seed_terms = ['clean', 'recovery', 'spiral', 'tolerance', 'program']
embeddings_ex = np.random.rand(5, 10, 2)
embeddings_ex = np.array(embeddings_ex)
words_ex = [['quit', 'finally', 'pill', 'vomit', 'survive' ,'lil', 'chance' ,'chain', 'zero',
'quickly'],
['bullshit' ,'unrelated', 'everywhere', 'appear' ,'probably' ,'deal',
'mistake', 'window', 'comment', 'honest'],
['majority' ,'familiar', 'queer', 'edgy', 'skin', 'withdrawl' ,'sad', 'develop',
'perfectly', 'daughter'],
['snort', 'cheap', 'brain', 'teach' ,'shoot' ,'inject' ,'freak', 'type', 'black',
'absolute'],
['substitution', 'suboxone', 'country' ,'clinic', 'nerve', 'representation',
'2', 'website' ,'youtuber', 'insane']]
words_ex = np.array(words_ex)
fig, ax = plt.subplots(figsize=(16, 9))
sc = embeddings_ex[:, :, 0].flatten()
sw = embeddings_ex[:, :, 1].flatten()
plt.scatter(sc, sw, s=45, marker='o', alpha=0.2, color="none", edgecolors='k')
# annotate(ax, sc, sw, words, size=11)
# fill points that are seed words and make font bold
# Okabe and Ito color palette
colors = ['#FA4D4D', '#FBC93D', '#E37E3B', '#C13BE3', '#4B42FD', '#D55E00', '#CC79A7']
for i, word in enumerate(seed_terms):
plt.scatter(sc[i], sw[i], marker='o', alpha=.9,
color=colors[i], edgecolors='none', s = 100)
plt.annotate(word, alpha=.5, xy=(sc[i], sw[i]), xytext=(
5, 2), textcoords='offset points', ha='right', va='bottom', size=11)
# annotate similar words
for word in seed_terms:
# get the index of the seed word in the list of seed words
idx = seed_terms.index(word)
# get the x and y coordinates of the seed word
x = embeddings_ex[idx, :, 0].flatten()
y = embeddings_ex[idx, :, 1].flatten()
# get the list of similar words
similar_words = words_ex[idx]
# add annotations with smaller font
annotate(ax, x, y, similar_words, size=6)
# legend
plt.legend(seed_terms, loc=4)
plt.grid(False)
# remove axes and frame
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
# ticks
plt.tick_params(axis='both', which='both', bottom=False,
left=False, labelbottom=False, labelleft=False)
CodePudding user response:
The word groups related to the central keyword are taken from the five arrays in a list and are about to be annotated, but since the related word groups are a list, a loop process is required to add scattering and annotation. One thing to be careful of in this method is the order in which the scatter and annotations are drawn. First we need to draw the gray scatter plot, then the scatter and annotations for the related terms, and finally the scatter and annotations for the central terms. The reason is that everything is drawn with the same coordinate data, so the hollow markers will be overwritten after the fill. The attached image controls the overlapping of the annotations, which I assume cannot be achieved with matplotlib alone, so perhaps some other tool is being introduced.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(20230115)
seed_terms = ['clean', 'recovery', 'spiral', 'tolerance', 'program']
embeddings_ex = np.random.rand(5, 10, 2)
embeddings_ex = np.array(embeddings_ex)
words_ex = [['quit', 'finally', 'pill', 'vomit', 'survive' ,'lil', 'chance' ,'chain', 'zero', 'quickly'],
['bullshit' ,'unrelated', 'everywhere', 'appear' ,'probably' ,'deal', 'mistake', 'window', 'comment', 'honest'],
['majority' ,'familiar', 'queer', 'edgy', 'skin', 'withdrawl' ,'sad', 'develop', 'perfectly', 'daughter'],
['snort', 'cheap', 'brain', 'teach' ,'shoot' ,'inject' ,'freak', 'type', 'black', 'absolute'],
['substitution', 'suboxone', 'country' ,'clinic', 'nerve', 'representation', '2', 'website' ,'youtuber', 'insane']]
words_ex = np.array(words_ex)
fig, ax = plt.subplots(figsize=(16, 9))
sc = embeddings_ex[:, :, 0].flatten()
sw = embeddings_ex[:, :, 1].flatten()
plt.scatter(sc, sw, s=45, marker='o', alpha=0.2, color="none", edgecolors='k')
# fill points that are seed words and make font bold
# Okabe and Ito color palette
colors = ['#FA4D4D', '#FBC93D', '#E37E3B', '#C13BE3', '#4B42FD', '#D55E00', '#CC79A7']
# annotate similar words
for word in seed_terms:
# get the index of the seed word in the list of seed words
idx = seed_terms.index(word)
# get the x and y coordinates of the seed word
x = embeddings_ex[idx, :, 0].flatten()
y = embeddings_ex[idx, :, 1].flatten()
# get the list of similar words
similar_words = words_ex[idx]
# add annotations with smaller font
for w,xx,yy in zip(similar_words, x,y):
plt.scatter(xx, yy, s=45, marker='o', color='white', edgecolors=colors[idx])
plt.annotate(w, xy=(xx, yy), xytext=(5,2), textcoords='offset points', ha='right',va='bottom', size=6)
for i, word in enumerate(seed_terms):
plt.scatter(sc[i], sw[i], marker='o', alpha=.9, color=colors[i], edgecolors='none', s=100, label=word)
plt.annotate(word, alpha=.5, xy=(sc[i], sw[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=11)
# legend
plt.legend(loc=4)
plt.grid(False)
# remove axes and frame
plt.gca().spines[:].set_visible(False)
# ticks
plt.tick_params(axis='both', which='both', bottom=False,
left=False, labelbottom=False, labelleft=False)
plt.show()

CodePudding user response:
To make the points similar to the seed terms have the same color as the filled points (seed terms), you can change the line:
plt.scatter(sc, sw, s=45, marker='o', alpha=0.2, color="none", edgecolors='k')
to:
plt.scatter(sc, sw, s=45, marker='o', alpha=0.2, color=colors[i], edgecolors='k')
and add
i = seed_terms.index(word)
before the line where you are using the scatter function.
Regarding the first word being white, it is likely because the first color in the colors array is '#FA4D4D', which is a reddish color.