I have pandas dataframe that contains data given below
ID Q1_rev Q1_transcnt Q2_rev Q2_transcnt Q3_rev Q3_transcnt Q4_rev Q4_transcnt
1 100 2 200 4 300 6 400 8
2 101 3 201 5 301 7 401 9
dataframe looks like below

I would like to do the below
a) For each ID, create 3 rows (from 8 input columns data)
b) Each row should contain the two columns data
c) subsequent rows should shift the columns by 1 (one quarter data).
To understand better, I expect my output to be like as below
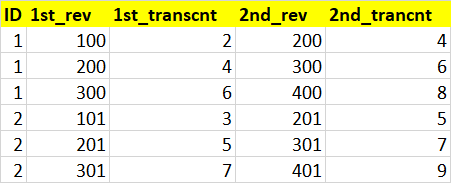
I tried the below based on the SO post here but unable to get the expected output
s = 3
n = 2
cols = ['1st_rev','1st_transcnt','2nd_rev','2nd_transcnt']
output = pd.concat((df.iloc[:,0 i*s:6 i*s].set_axis(cols, axis=1) for i in range(int((df.shape[1]-(s*n))/n))), ignore_index=True, axis=0).set_index(np.tile(df.index,2))
Can help me with this? The problem is in real time, n=2 will not be the case. It could be 4 or 5 as well. Meaning, Instead of '1st_rev','1st_transcnt','2nd_rev','2nd_transcnt', I may have the below. You can see there are 4 pairs of columns.
'1st_rev','1st_transcnt','2nd_rev','2nd_transcnt','3rd_rev','3rd_transcnt','4th_rev','4th_transcnt'
CodePudding user response:
Use custom function with DataFrame.groupby by splitted columns names by _ and selected second splitted substring by x.split('_')[1]:
N = 2
df1 = df.set_index('ID')
def f(x,n=N):
out = np.array([[list(L[x:x n]) for x in range(len(L)-n 1)] for L in x.to_numpy()])
return pd.DataFrame(np.vstack(out))
df2 = (df1.groupby(lambda x: x.split('_')[1], axis=1, sort=False)
.apply(f)
.sort_index(axis=1, level=1, sort_remaining=False))
df2.index = np.repeat(df1.index, int(len(df2.index) / len(df1.index)))
df2.columns = df2.columns.map(lambda x: f'{x[1] 1}_{x[0]}')
print (df2)
1_rev 1_transcnt 2_rev 2_transcnt
ID
1 100 2 200 4
1 200 4 300 6
1 300 6 400 8
2 101 3 201 5
2 201 5 301 7
2 301 7 401 9
Test with 3 window:
N = 3
df1 = df.set_index('ID')
def f(x,n=N):
out = np.array([[list(L[x:x n]) for x in range(len(L)-n 1)] for L in x.to_numpy()])
return pd.DataFrame(np.vstack(out))
df2 = (df1.groupby(lambda x: x.split('_')[1], axis=1, sort=False)
.apply(f)
.sort_index(axis=1, level=1, sort_remaining=False))
df2.index = np.repeat(df1.index, int(len(df2.index) / len(df1.index)))
df2.columns = df2.columns.map(lambda x: f'{x[1] 1}_{x[0]}')
print (df2)
1_rev 1_transcnt 2_rev 2_transcnt 3_rev 3_transcnt
ID
1 100 2 200 4 300 6
1 200 4 300 6 400 8
2 101 3 201 5 301 7
2 201 5 301 7 401 9
CodePudding user response:
One option is with a for loop or list comprehension, followed by a concatenation, and a sort:
temp = df.set_index('ID')
cols = ['1st_rev','1st_transcnt','2nd_rev','2nd_transcnt']
outcome = [temp
.iloc(axis=1)[n:n 4]
.set_axis(cols, axis = 1)
for n in range(0, len(cols) 2, 2)]
pd.concat(outcome).sort_index()
1st_rev 1st_transcnt 2nd_rev 2nd_transcnt
ID
1 100 2 200 4
1 200 4 300 6
1 300 6 400 8
2 101 3 201 5
2 201 5 301 7
2 301 7 401 9