I currently receive csv files in the following format:
Col1, Col2, Col3, Col4
Header1, , ,
Val1, Val2, Val3, Val4
Val1, Val2, Val3, Val4
Val1, Val2, Val3, Val4
Header2, , ,
Val1, Val2, Val3, Val4
Header3, , ,
Val1, Val2, Val3, Val4
Val1, Val2, Val3, Val4
The number of rows per header can vary and the Headers can contain any words.
The expected result should be one of: Option 1: Save headers to additional column in 1 file File: abc/abc/complete_output
Col1, Col2, Col3, Col4, Col5
Val1, Val2, Val3, Val4, Header1
Val1, Val2, Val3, Val4, Header1
Val1, Val2, Val3, Val4, Header1
Val1, Val2, Val3, Val4, Header2
Val1, Val2, Val3, Val4, Header3
Val1, Val2, Val3, Val4, Header3
Option 2: create different file per header: File1: abc/abc/Header1
Col1, Col2, Col3, Col4
Val1, Val2, Val3, Val4
Val1, Val2, Val3, Val4
Val1, Val2, Val3, Val4
File2: abc/abc/Header2
Col1, Col2, Col3, Col4
Val1, Val2, Val3, Val4
File3: abc/abc/Header3
Col1, Col2, Col3, Col4
Val1, Val2, Val3, Val4
Val1, Val2, Val3, Val4
The files should either be split from the received format to different files or the header rows should be mapped to an additional column. Can this be done in Azure Data Factory, including Data Flow options? There is no access to a Databricks cluster.
P.S. I know this would be easy with a Python script whatsoever, but I hope to be able to build the complete flow in ADF.
I tried splitting the file based on conditional split. However, this does not work, as this just allows to select rows. This could only be used if (one of) the row values gave an indication about the Header.
No other things seem usable to me.
Edit: added desired output options as asked
CodePudding user response:
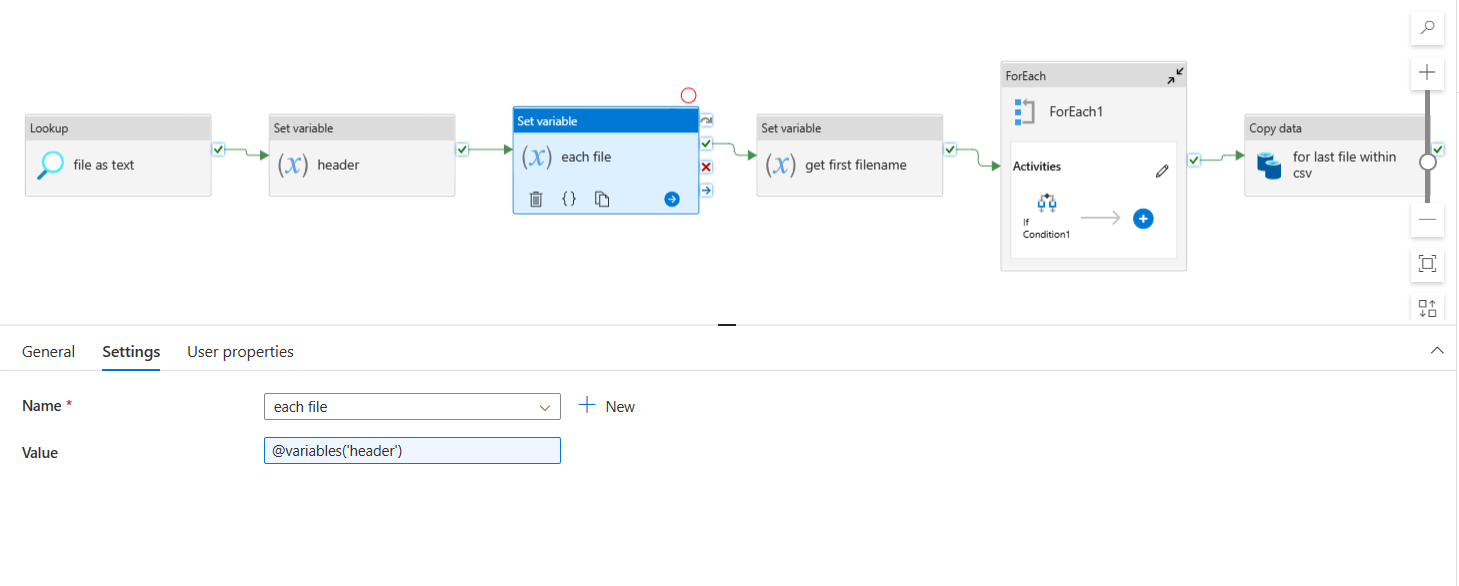
- You can achieve this with in data factory using variables, loops and conditionals and copy data activity.
- First, read the source file using look up activity without header and random row and column delimiters and without selecting
First row as headeroption (So that you would get the output as shown in below image.) I have used;as column delimiter and|as row delimiter and.
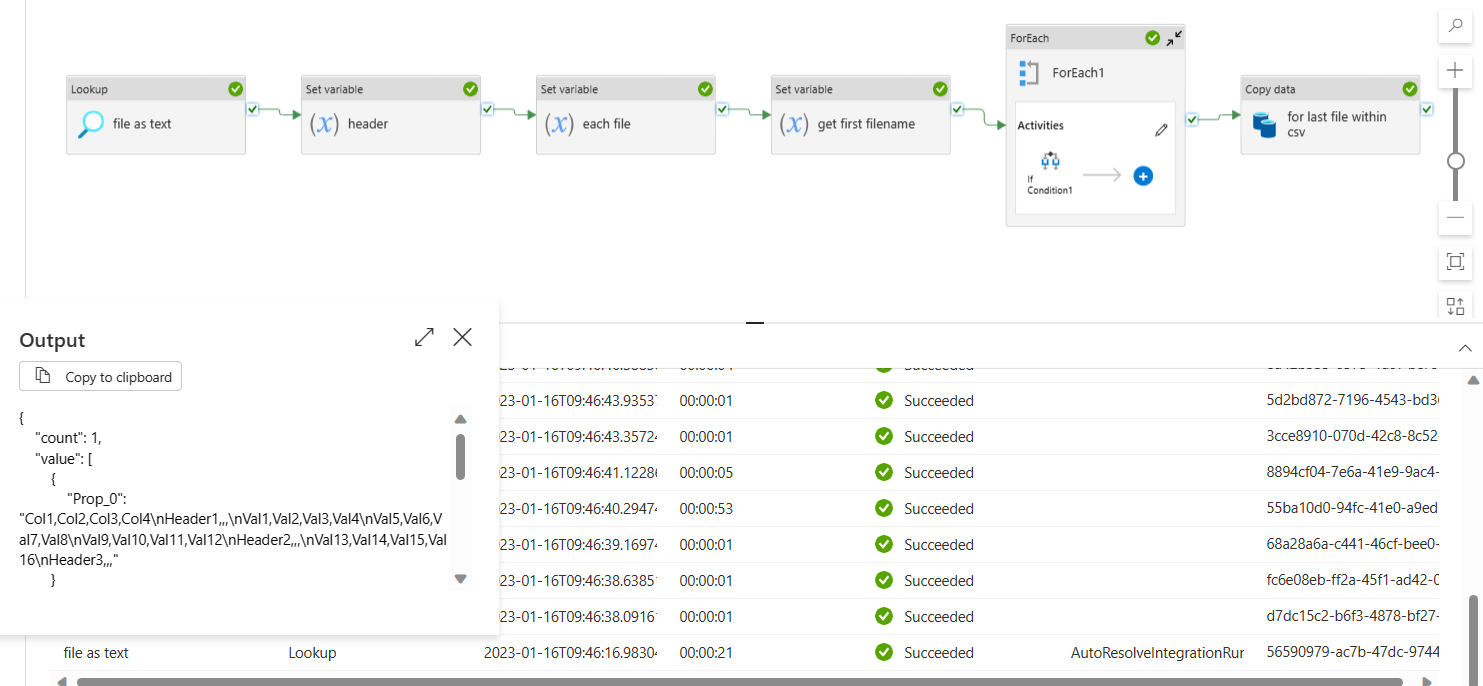
- Now, I have used multiple set variable activities. The
headeractivity is to extract the header (col1,col2,col3,col4) from lookup output.
@first(array(split(activity('file as text').output.value[0]['Prop_0'],decodeUriComponent('
'))))
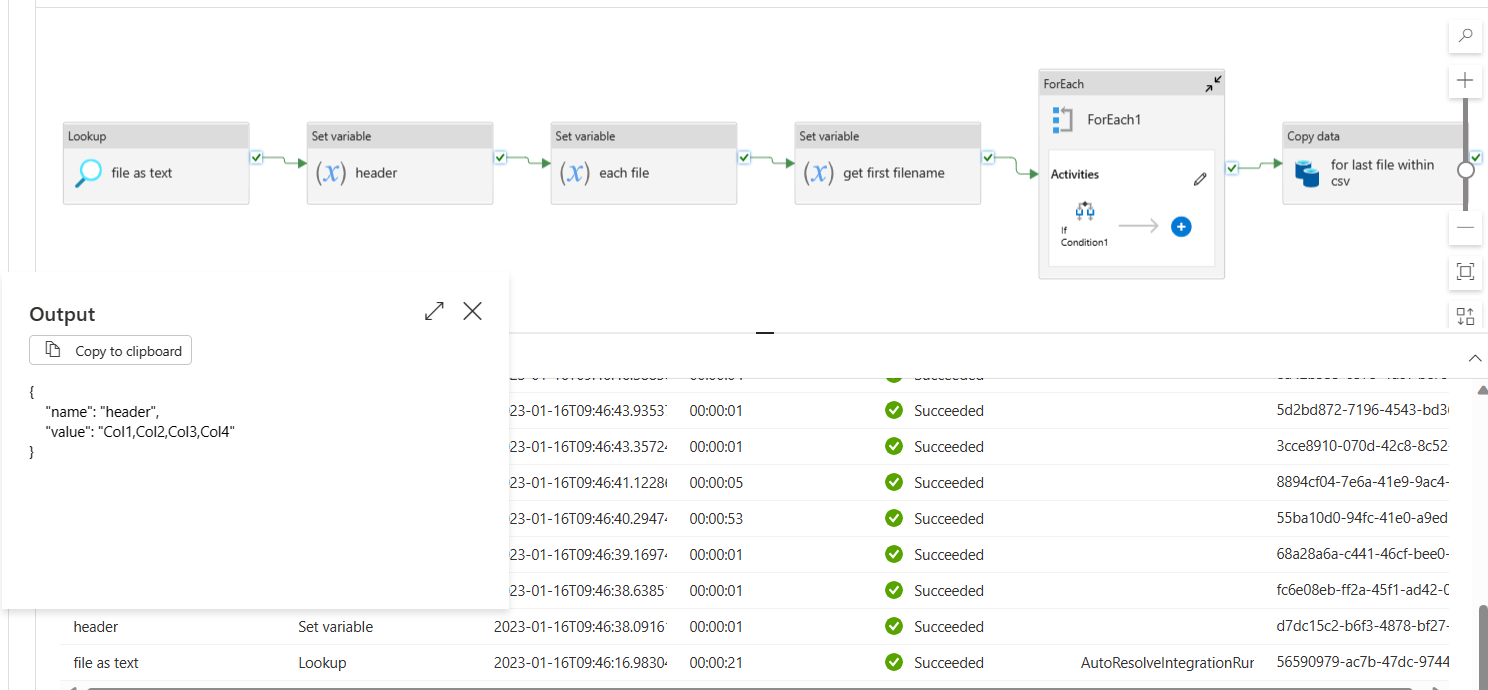
each fileset variable activity to store all the data for each file. I initialized it withheadervariable value.
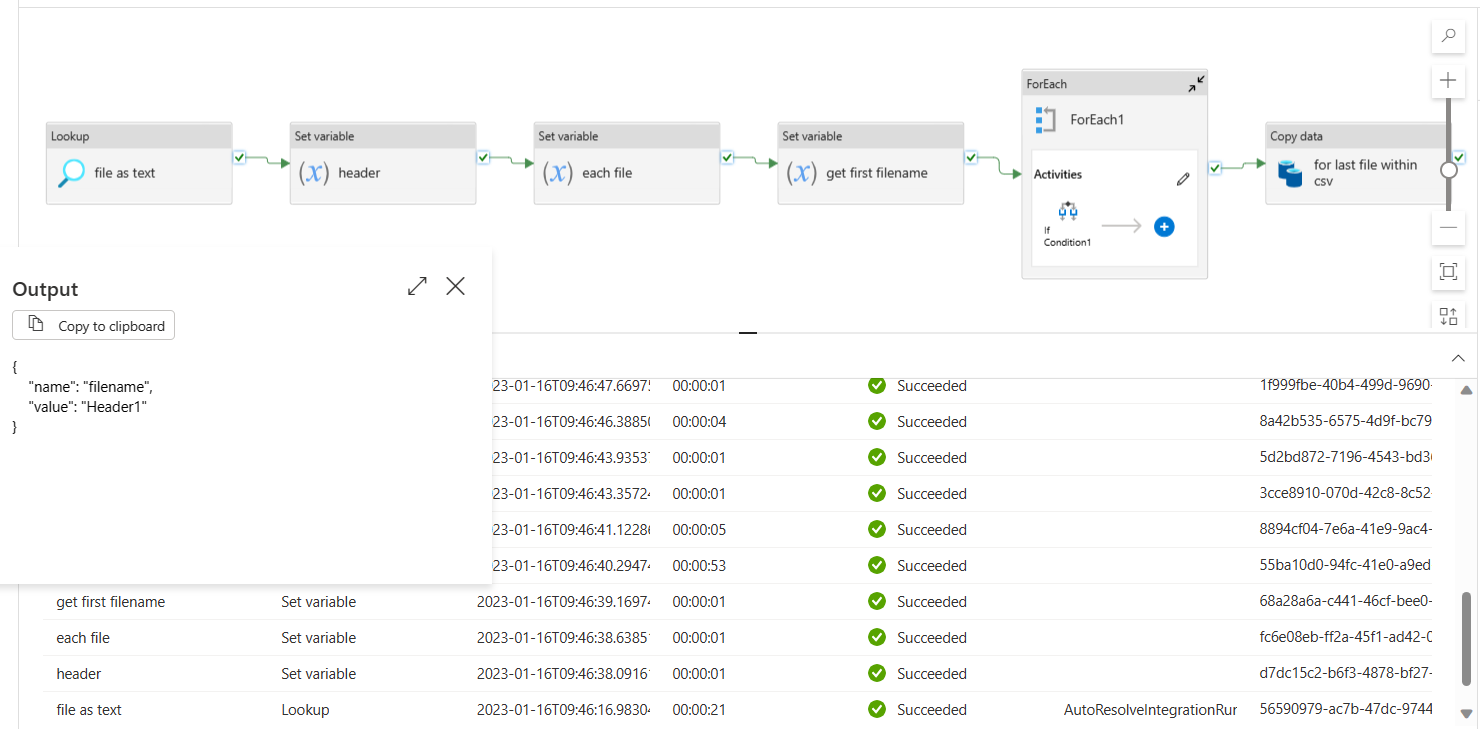
get first filenameis used to extract the name of first file (header1 in this case) using collection and string functions.
@replace(first(skip(array(split(activity('file as text').output.value[0]['Prop_0'],decodeUriComponent('
'))),1)),',,,','')
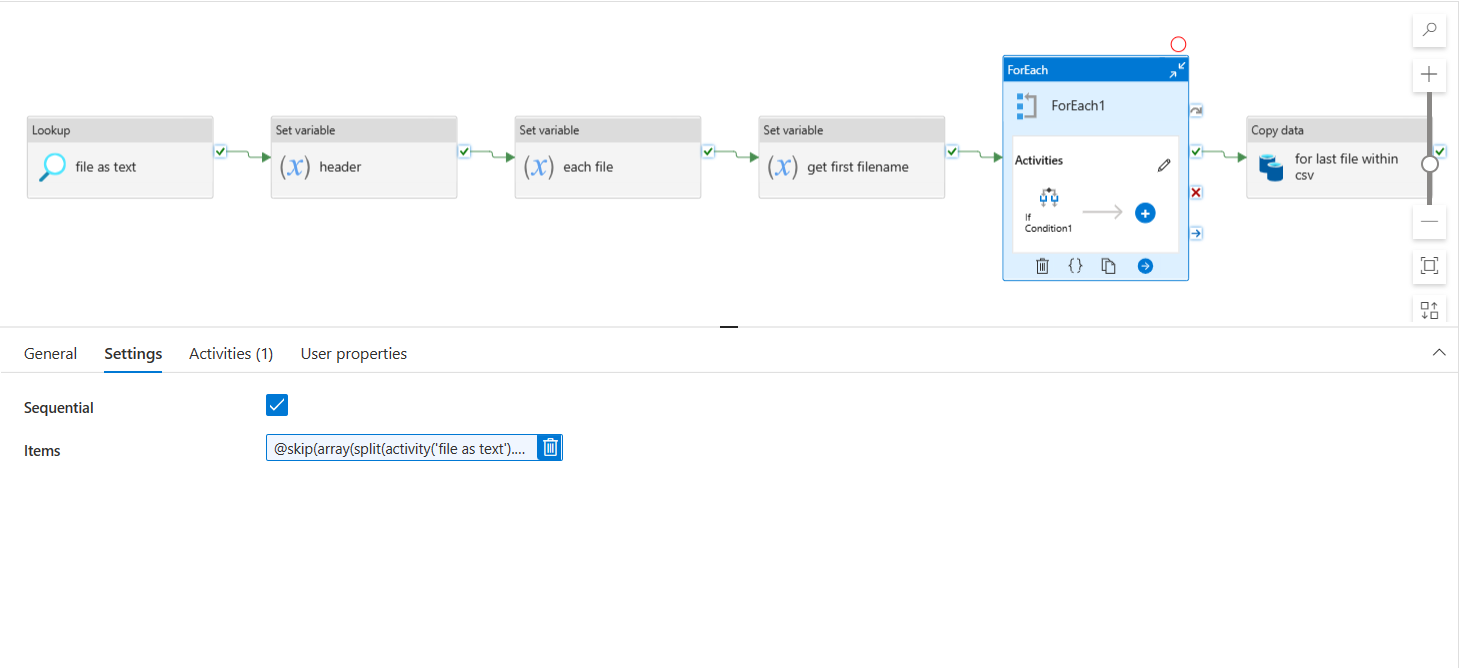
- Now, take the rest of the data (after header1 line), use it as items value in for each loop and then do further processing.
@skip(array(split(activity('file as text').output.value[0]['Prop_0'],decodeUriComponent('
'))),2)
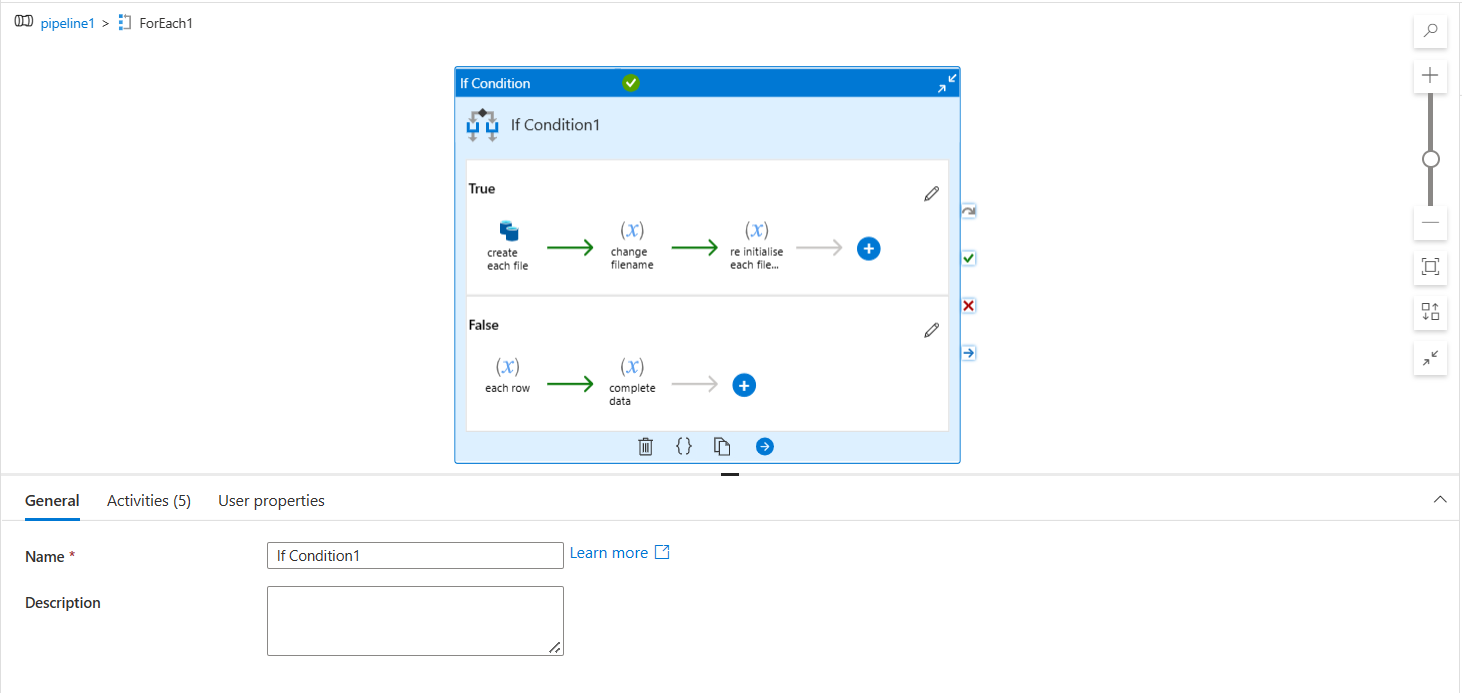
- Inside for each, I have an
if conditionactivity to check if the line is header (to be considered as filename) or not. Accordingly, I have concatenated each line accordingly and used copy data activity as per requirement.
- The following is the entire pipeline JSON (you can use this directly except that you have to create your datasets).
{
"name": "pipeline1",
"properties": {
"activities": [
{
"name": "file as text",
"type": "Lookup",
"dependsOn": [],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"dataset": {
"referenceName": "csv1",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
"name": "header",
"type": "SetVariable",
"dependsOn": [
{
"activity": "file as text",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "header",
"value": {
"value": "@first(array(split(activity('file as text').output.value[0]['Prop_0'],decodeUriComponent('
'))))",
"type": "Expression"
}
}
},
{
"name": "each file",
"type": "SetVariable",
"dependsOn": [
{
"activity": "header",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "each file",
"value": {
"value": "@variables('header')",
"type": "Expression"
}
}
},
{
"name": "get first filename",
"type": "SetVariable",
"dependsOn": [
{
"activity": "each file",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "filename",
"value": {
"value": "@replace(first(skip(array(split(activity('file as text').output.value[0]['Prop_0'],decodeUriComponent('
'))),1)),',,,','')",
"type": "Expression"
}
}
},
{
"name": "ForEach1",
"type": "ForEach",
"dependsOn": [
{
"activity": "get first filename",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"items": {
"value": "@skip(array(split(activity('file as text').output.value[0]['Prop_0'],decodeUriComponent('
'))),2)",
"type": "Expression"
},
"isSequential": true,
"activities": [
{
"name": "If Condition1",
"type": "IfCondition",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"expression": {
"value": "@contains(item(),',,,')",
"type": "Expression"
},
"ifFalseActivities": [
{
"name": "each row",
"type": "SetVariable",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"variableName": "each row",
"value": {
"value": "@concat(variables('each file'),decodeUriComponent('
'),item())",
"type": "Expression"
}
}
},
{
"name": "complete data",
"type": "SetVariable",
"dependsOn": [
{
"activity": "each row",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "each file",
"value": {
"value": "@variables('each row')",
"type": "Expression"
}
}
}
],
"ifTrueActivities": [
{
"name": "create each file",
"type": "Copy",
"dependsOn": [],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"additionalColumns": [
{
"name": "req",
"value": {
"value": "@variables('each file')",
"type": "Expression"
}
}
],
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobFSWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".txt"
}
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "req",
"type": "String"
},
"sink": {
"type": "String",
"physicalType": "String",
"ordinal": 1
}
}
],
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "demo",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "op_files",
"type": "DatasetReference",
"parameters": {
"fileName": {
"value": "@variables('filename')",
"type": "Expression"
}
}
}
]
},
{
"name": "change filename",
"type": "SetVariable",
"dependsOn": [
{
"activity": "create each file",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "filename",
"value": {
"value": "@replace(item(),',,,','')",
"type": "Expression"
}
}
},
{
"name": "re initialise each file value",
"type": "SetVariable",
"dependsOn": [
{
"activity": "change filename",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "each file",
"value": {
"value": "@variables('header')",
"type": "Expression"
}
}
}
]
}
}
]
}
},
{
"name": "for last file within csv",
"type": "Copy",
"dependsOn": [
{
"activity": "ForEach1",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"additionalColumns": [
{
"name": "req",
"value": {
"value": "@variables('each file')",
"type": "Expression"
}
}
],
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobFSWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".txt"
}
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "req",
"type": "String"
},
"sink": {
"type": "String",
"physicalType": "String",
"ordinal": 1
}
}
],
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "demo",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "op_files",
"type": "DatasetReference",
"parameters": {
"fileName": {
"value": "@variables('filename')",
"type": "Expression"
}
}
}
]
}
],
"variables": {
"header": {
"type": "String"
},
"each file": {
"type": "String"
},
"filename": {
"type": "String"
},
"each row": {
"type": "String"
}
},
"annotations": []
}
}
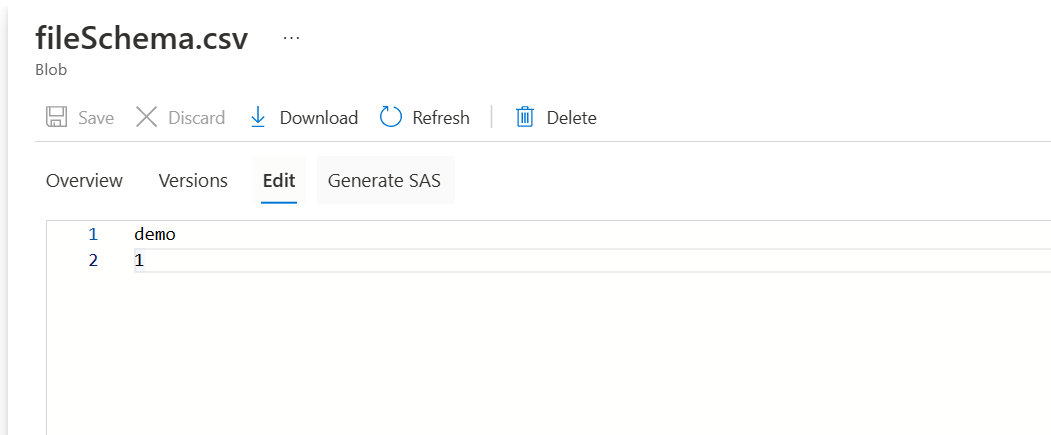
- For copy data, the source data looks as shown below:
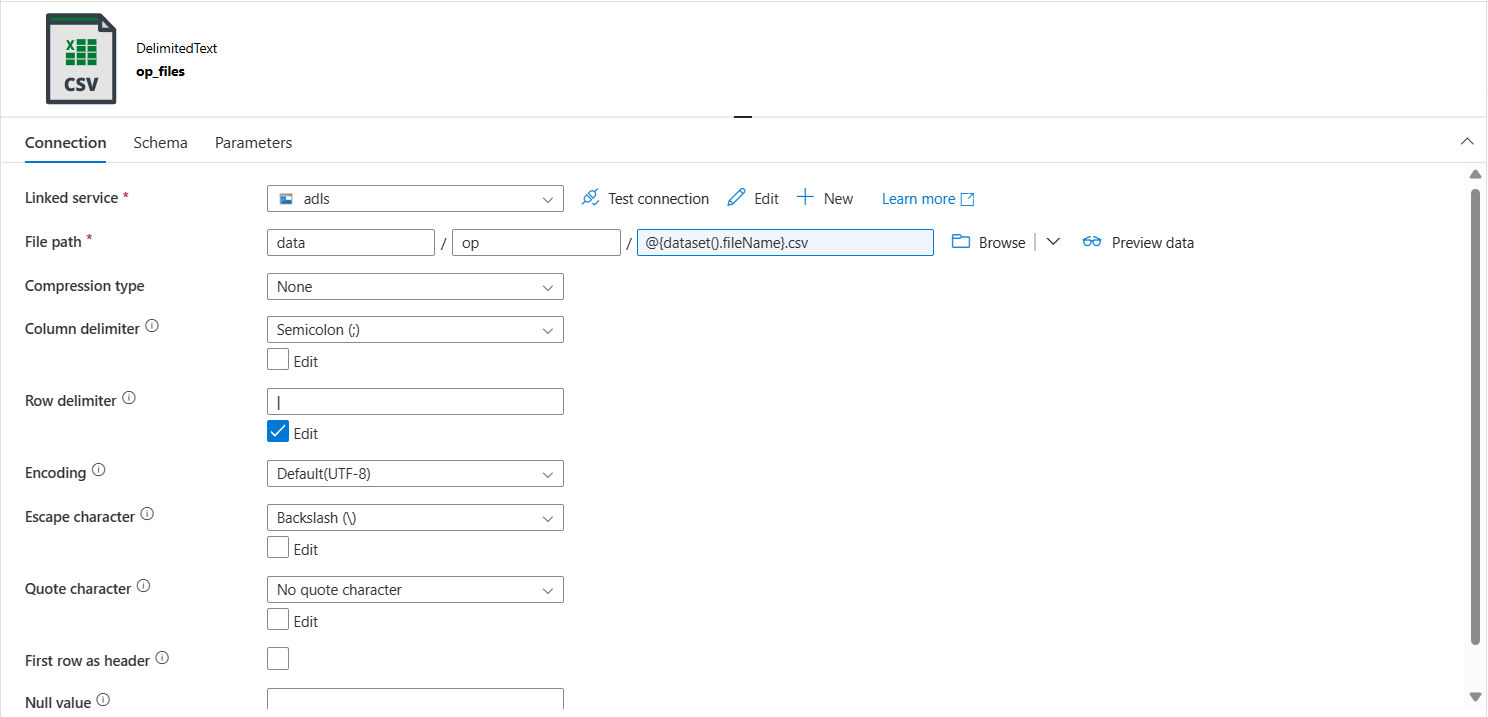
- The sink of the copy data activity has the following dataset configurations (both source and sink dataset are same in 2 copy data activities):
- The following are the outputs for each of the file for given sample data:
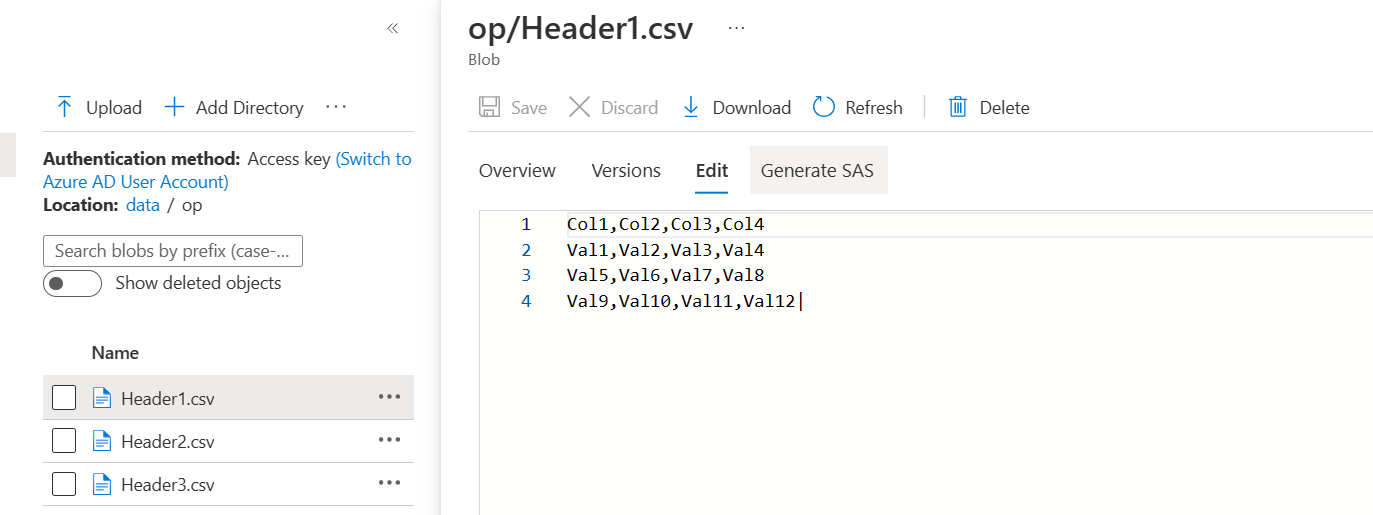
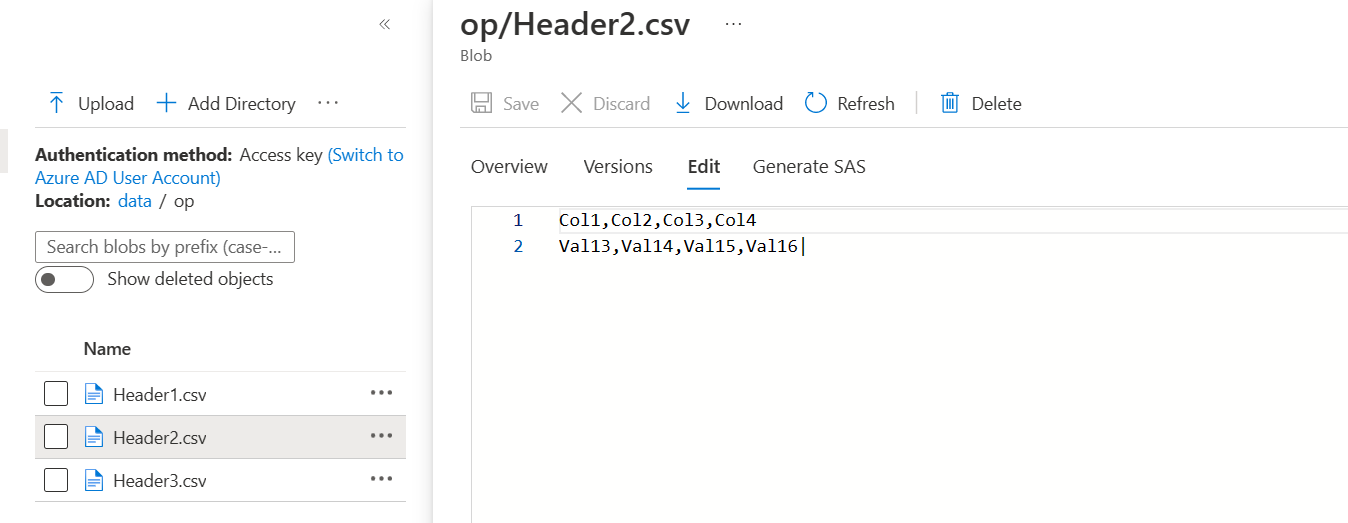
- If the file ends with data (not header) then the file would be populated as required instead of empty file with just header.
CodePudding user response:
If the input dataset is static, considering the second option as requirement then you can go with the following approach:
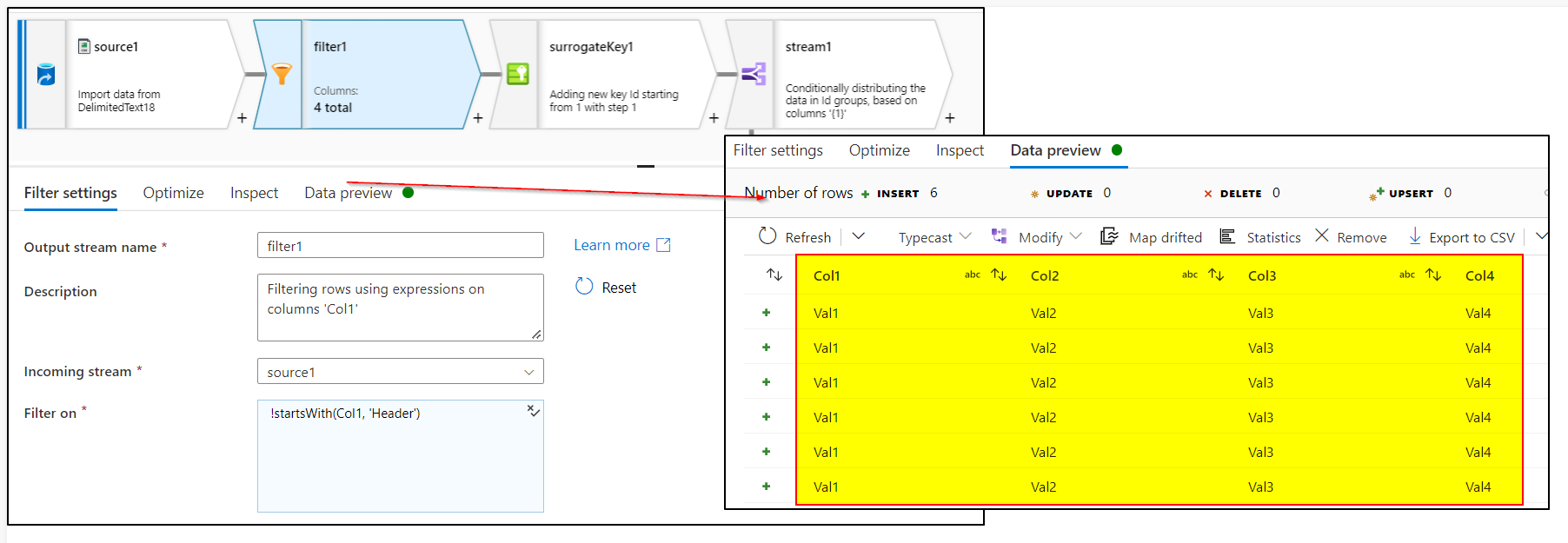
Add Filter transformation after source with expression as :
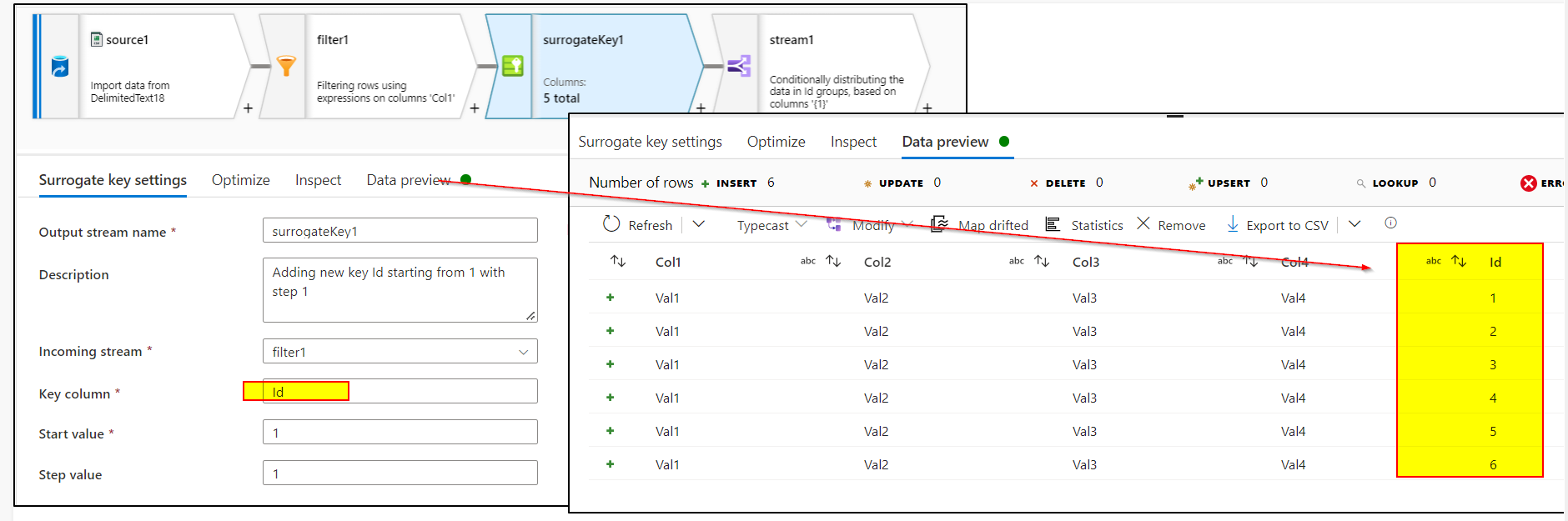
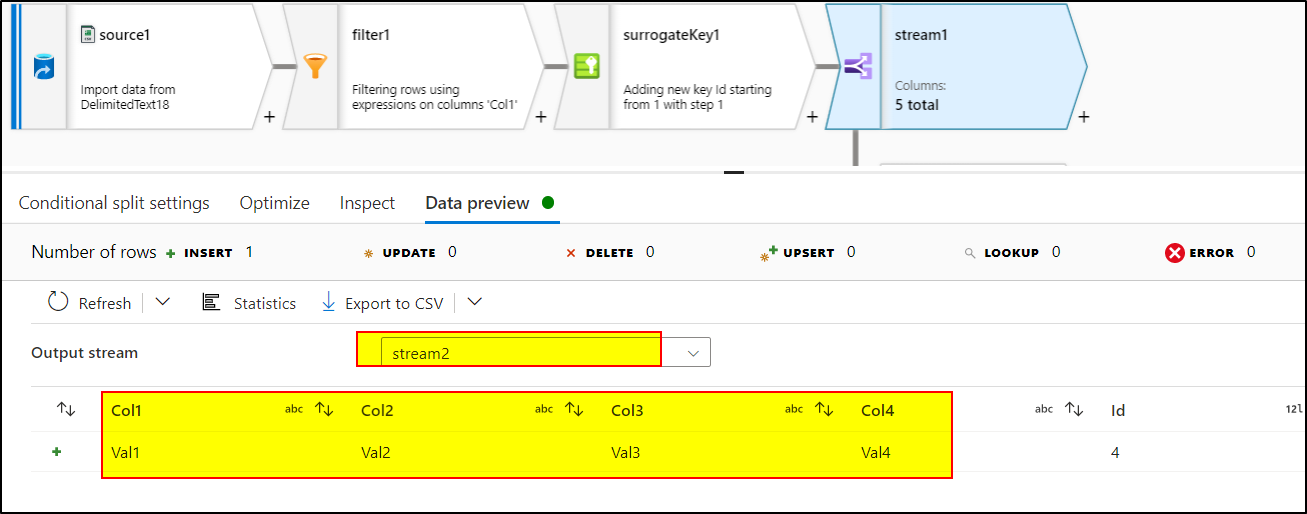
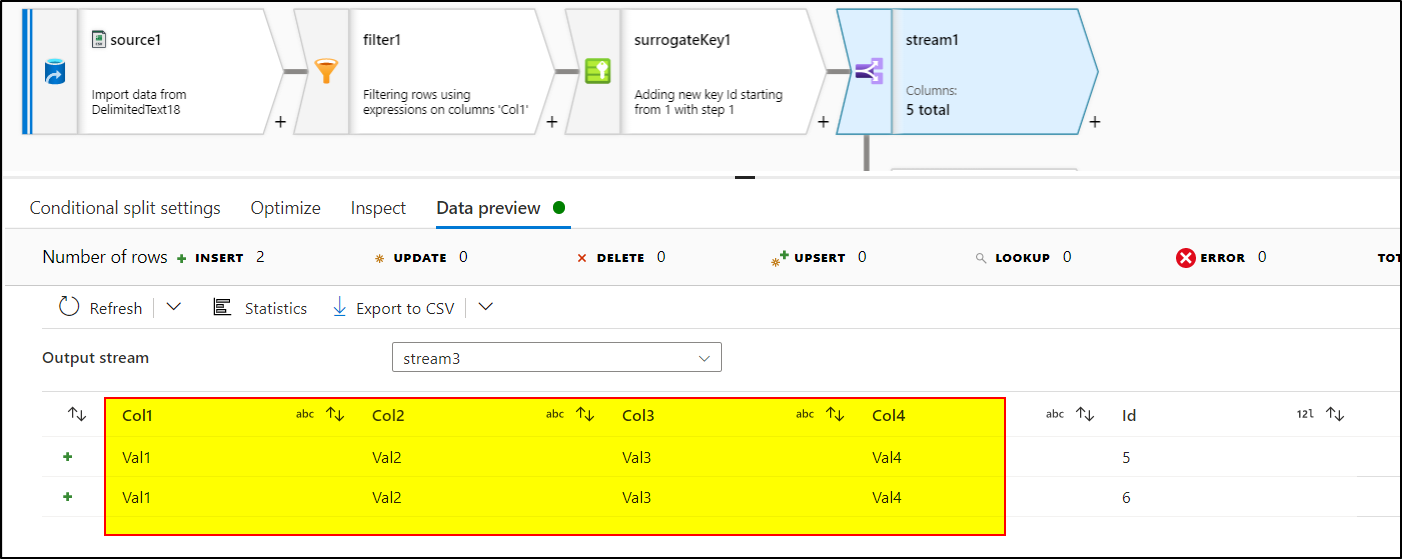
!startsWith(Col1, 'Header')Add surrogate key transformation to create the incremental identity column
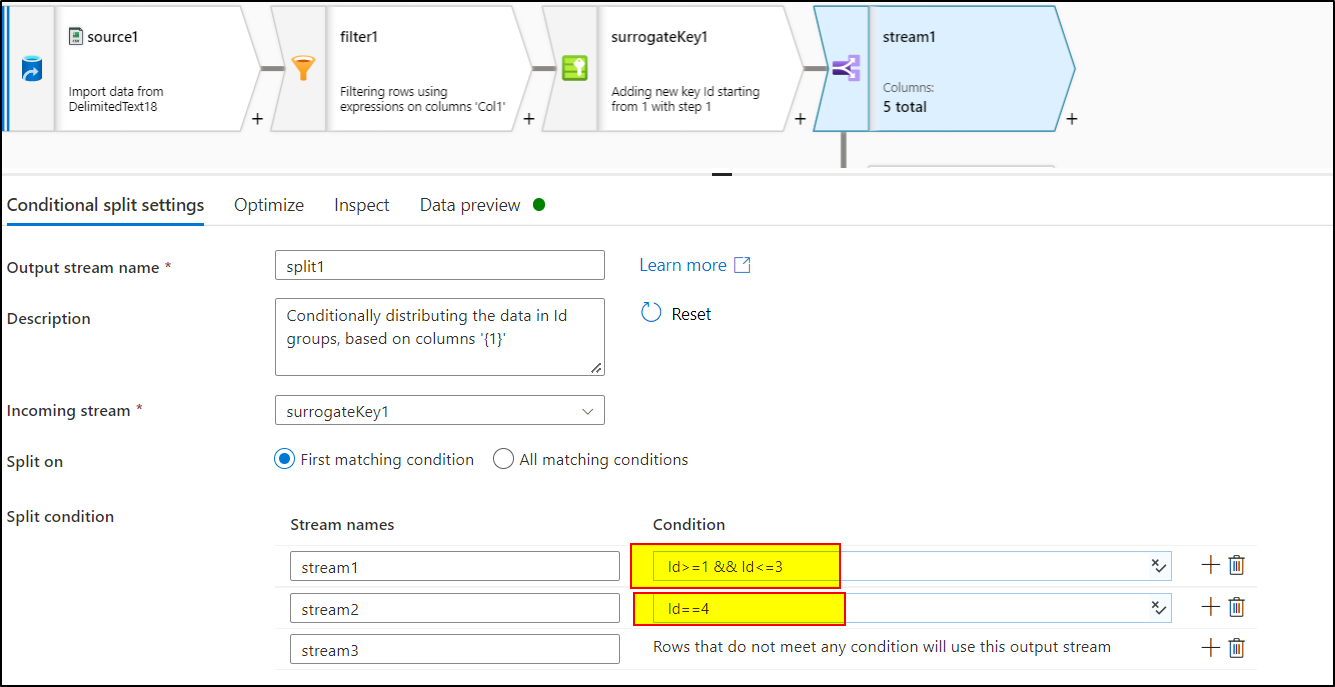
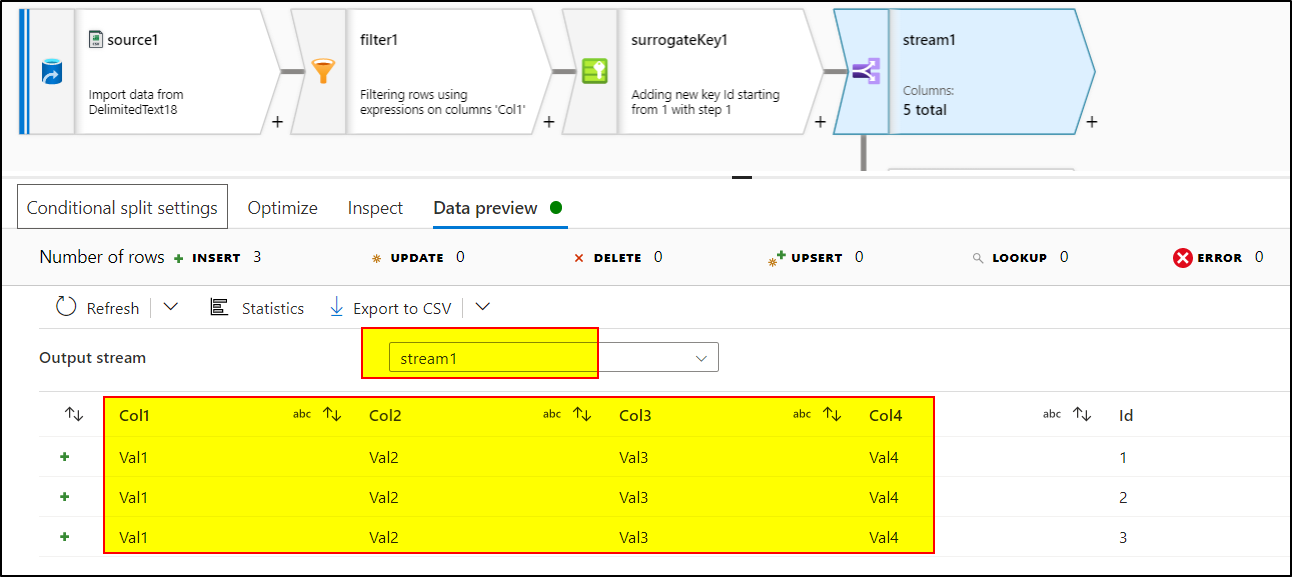
Add conditional split transformation to split the data into three parts having these expressions:
stream1:Id>=1 && Id<=3stream2:Id==4stream3 :DefaultUse Select transformation to deselect 'Id' column
Add sink transformation to load the data to csv file