I have a dataframe like as shown below
sample_df = pd.DataFrame({'single_proj_name': [['jsfk'],['fhjk'],['ERRW'],['SJBAK']],
'single_item_list': [['ABC_123'],['DEF123'],['FAS324'],['HSJD123']],
'single_id':[[1234],[5678],[91011],[121314]],
'multi_proj_name':[['AAA','VVVV','SASD'],['QEWWQ','SFA','JKKK','fhjk'],['ERRW','TTTT'],['SJBAK','YYYY']],
'multi_item_list':[[['XYZAV','ADS23','ABC_123'],['ABC_123','ADC_123']],['XYZAV','DEF123','ABC_123','SAJKF'],['QWER12','FAS324'],['JFAJKA','HSJD123']],
'multi_id':[[[2167,2147,29481],[5432,1234]],[2313,57567,2321,7898],[1123,8775],[5237,43512]]})
I would like to do the below
a) Pick the value from single_item_list for each row
b) search that value in multi_item_list column of the same row
c) If match found, keep only that value in multi_item_list and remove all other non-matching values from multi_item_list
d) Based on the position of the match item, look for corresponding value in multi_id list and keep only that item. Remove all other position items from the list
So, I tried the below but it doesn't work
def func(df):
return list(set(sample_df['single_item_list']) - set(sample_df['multi_item_list']))
sample_df['col3'] = sample_df.apply(func, axis = 1)
I expect my output to be like as below
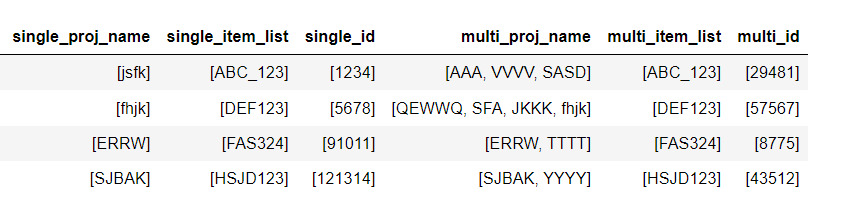
CodePudding user response:
You can explode the two lists in parallel (pandas 1.3 ), and filter:
(sample_df
.explode(['multi_item_list', 'multi_id'])
.loc[lambda d: d['single_item_list'].str[0].eq(d['multi_item_list'])]
)
If you want your lists back:
(sample_df
.explode(['multi_item_list', 'multi_id'])
.loc[lambda d: d['single_item_list'].str[0].eq(d['multi_item_list'])]
.assign(multi_item_list=lambda d: d['multi_item_list'].apply(lambda x: [x]),
multi_id=lambda d: d['multi_id'].apply(lambda x: [x]),
)
)
Output:
single_proj_name single_item_list single_id multi_proj_name multi_item_list multi_id
0 [jsfk] [ABC_123] [1234] [AAA, VVVV, SASD] [ABC_123] [29481]
1 [fhjk] [DEF123] [5678] [QEWWQ, SFA, JKKK, fhjk] [DEF123] [57567]
2 [ERRW] [FAS324] [91011] [ERRW, TTTT] [FAS324] [8775]
3 [SJBAK] [HSJD123] [121314] [SJBAK, YYYY] [HSJD123] [43512]
alternative using a list comprehension:
sample_df[['multi_item_list', 'multi_id']] = \
pd.DataFrame([next(([[x], [c[i]]] for i,x in enumerate(b) if x==a[0]), None)
for a, b, c in
zip(sample_df['single_item_list'],
sample_df['multi_item_list'],
sample_df['multi_id'])],
columns=['multi_item_list', 'multi_id'])