I have the following dataset:
#Load the required libraries
import pandas as pd
#Create dataset
data = {'id': [1, 1, 1, 1, 1,1, 1, 1, 1, 1,1, 1, 1, 1, 1,
2, 2, 2, 2, 2, 2,2,2,2,2,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
'Salary': [7, 7, 7, 7, 7,7,7,8,9,10,11,12,13,14,15,
4, 4, 4,4,5,6,7,8,9,10,
8, 8, 8, 8,8,8,8,8,9,10,11,12,13],
'Children': ['No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'No','No', 'Yes', 'Yes', 'Yes', 'No',
'Yes', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No',
'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'No','Yes', 'Yes', 'No','No', 'Yes'],
'Days': [123, 128, 66, 120, 141,123, 128, 66, 120, 141, 52,96, 120, 141, 52,
96, 120,120, 141, 52,96,128, 66, 120, 141,
120, 141,123,15,85,36,58,89,123, 128, 66, 120, 141],
}
#Convert to dataframe
df = pd.DataFrame(data)
print("df = \n", df)
The above dataset looks as such:
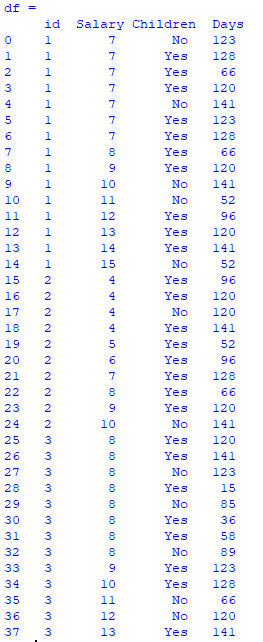
I wish to delete the rows with same entries from 'Salary' with respect to specific group/id.
For example,
For id = 1, delete rows with 'Salary'=7, except the last entry.
For id = 2, delete rows with 'Salary'=4, except the last entry.
For id = 3, delete rows with 'Salary'=8, except the last entry.
The new dataset should look as such:
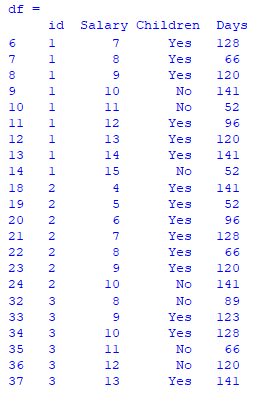
Can somebody please let me know hot to achieve this task in Python?
CodePudding user response:
Use boolean indexing with chain by & for bitwise AND and | for bitwise OR with DataFrame.duplicated:
mask = ((df['id'].ne(1) & df['Salary'].ne(7) &
df['id'].ne(2) & df['Salary'].ne(4) &
df['id'].ne(3) & df['Salary'].ne(8)) |
~df.duplicated(['id','Salary'], keep='last'))
df = df[mask]
print("df = \n", df)
id Salary Children Days
6 1 7 Yes 128
7 1 8 Yes 66
8 1 9 Yes 120
9 1 10 No 141
10 1 11 No 52
11 1 12 Yes 96
12 1 13 Yes 120
13 1 14 Yes 141
14 1 15 No 52
18 2 4 Yes 141
19 2 5 Yes 52
20 2 6 Yes 96
21 2 7 Yes 128
22 2 8 Yes 66
23 2 9 Yes 120
24 2 10 No 141
32 3 8 No 89
33 3 9 Yes 123
34 3 10 Yes 128
35 3 11 No 66
36 3 12 No 120
37 3 13 Yes 141
EDIT: If need only removed all duplicates with keep last rows per id,Salary columns use DataFrame.drop_duplicates :
df = df.drop_duplicates(subset=['id','Salary'], keep='last')
CodePudding user response:
try : drop_duplicates()
df = df.apply(lambdax:x.astype(str).str.lower()).drop_duplicates(subset='id','Salary'], keep='last')
new output
df =
id Salary Children Days
6 1 7 yes 128
7 1 8 yes 66
8 1 9 yes 120
9 1 10 no 141
10 1 11 no 52
11 1 12 yes 96
12 1 13 yes 120
13 1 14 yes 141
14 1 15 no 52
18 2 4 yes 141
19 2 5 yes 52
20 2 6 yes 96
21 2 7 yes 128
22 2 8 yes 66
23 2 9 yes 120
24 2 10 no 141
32 3 8 no 89
33 3 9 yes 123
34 3 10 yes 128
35 3 11 no 66
36 3 12 no 120
37 3 13 yes 141