beginner here. I have a dataframe like this:
df<-data.frame(Country=c("USA","USA","USA","USA","India","India","India","India","China","China","China","China"),
Indicator=rep(c("Population","GDP","Debt","Currency"),times=3),`2011`=rep(c(1,2,3,4),each=3),`2012`=rep(c(4,5,6,7),each=3),`2013`=rep(c(8,9,11,12),each=3))
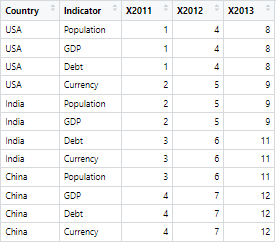
And I want to transpose and transform it so that it looks like this:
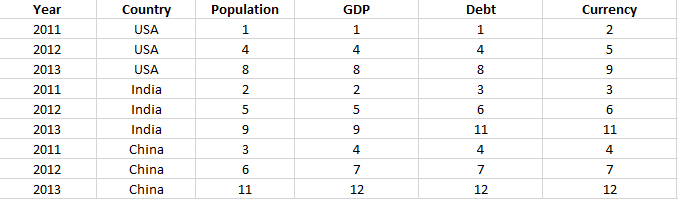
I would like to know if there is a streamlined way to do this. Thanks a lot in advance!
CodePudding user response:
library(tidyverse)
df %>%
pivot_longer(
starts_with("X"),
names_to = "Year",
names_transform = list(Year = parse_number)
) %>%
pivot_wider(names_from = Indicator, values_from = value) %>%
relocate(Year)
# A tibble: 9 × 6
Year Country Population GDP Debt Currency
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 2011 USA 1 1 1 2
2 2012 USA 4 4 4 5
3 2013 USA 8 8 8 9
4 2011 India 2 2 3 3
5 2012 India 5 5 6 6
6 2013 India 9 9 11 11
7 2011 China 3 4 4 4
8 2012 China 6 7 7 7
9 2013 China 11 12 12 12
CodePudding user response:
This is straightforward with the tidyverse
library(tidyverse)
#> Warning: package 'tidyr' was built under R version 4.1.3
#> Warning: package 'readr' was built under R version 4.1.3
#> Warning: package 'dplyr' was built under R version 4.1.3
df<-data.frame(Country=c("USA","USA","USA","USA","India","India","India","India","China","China","China","China"),
Indicator=rep(c("Population","GDP","Debt","Currency"),times=3),`2011`=rep(c(1,2,3,4),each=3),`2012`=rep(c(4,5,6,7),each=3),`2013`=rep(c(8,9,11,12),each=3))
df |>
pivot_longer(cols = contains('20')) |>
pivot_wider(names_from = Indicator,values_from = value)
#> # A tibble: 9 x 6
#> Country name Population GDP Debt Currency
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 USA X2011 1 1 1 2
#> 2 USA X2012 4 4 4 5
#> 3 USA X2013 8 8 8 9
#> 4 India X2011 2 2 3 3
#> 5 India X2012 5 5 6 6
#> 6 India X2013 9 9 11 11
#> 7 China X2011 3 4 4 4
#> 8 China X2012 6 7 7 7
#> 9 China X2013 11 12 12 12
Created on 2023-01-19 by the reprex package (v2.0.1)
CodePudding user response:
Please try the below code
df2 <- df %>% pivot_longer(c(starts_with('X')), names_to = 'year') %>%
mutate(year=as.numeric(str_replace(year,'\\w',' '))) %>%
pivot_wider(c('year','Country'), names_from = 'Indicator', values_from = 'value')
# A tibble: 9 × 6
year Country Population GDP Debt Currency
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 2011 USA 1 1 1 2
2 2012 USA 4 4 4 5
3 2013 USA 8 8 8 9
4 2011 India 2 2 3 3
5 2012 India 5 5 6 6
6 2013 India 9 9 11 11
7 2011 China 3 4 4 4
8 2012 China 6 7 7 7
9 2013 China 11 12 12 12