I have plot 100 lines. Each line has color based on score. It is very difficult to see any pattern in the figure because lines overlap.
Is there a better representation which shows lines and scores are linked to one another.
I believe some kind of density plot can show the pattern.
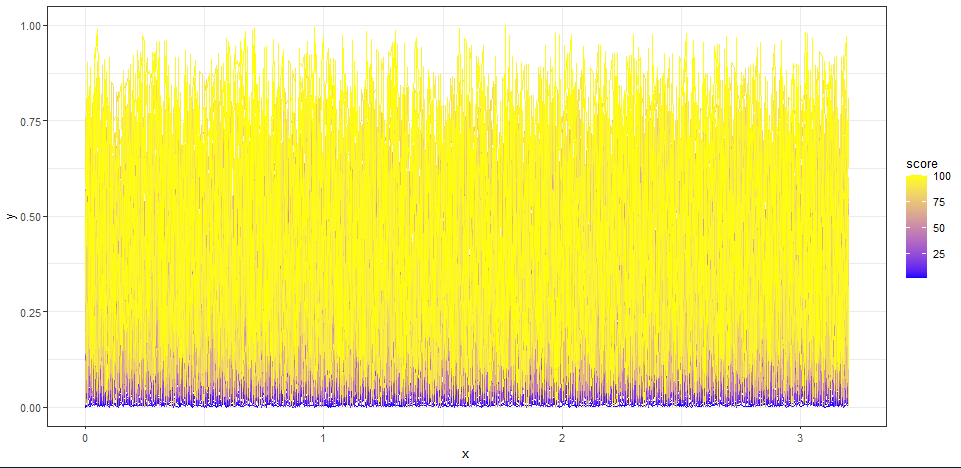
library(tidyverse)
x <- rep(seq(0, 3.2, 0.01), times = 100)
score <- rep(1:100, each = 321)
y = runif(1000) * score * 0.01
df <- tibble(x = x,
score = score,
y = y)
ggplot(data = df,
aes(x = x,
y = y,
group = score,
color = score))
geom_line(size = 0.15)
theme_bw()
theme(aspect.ratio = 0.5)
# legend.position="none")
scale_color_gradient(low = 'blue', high = 'yellow')
CodePudding user response:
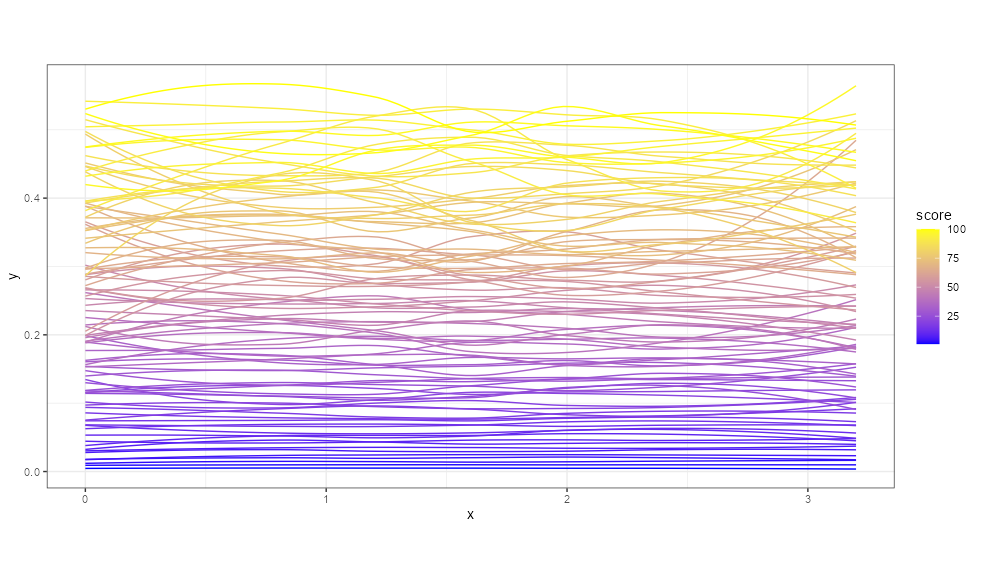
The sample data is simply too messy and complex to show in an unfiltered line plot. One option is to show a summary of each line via geom_smooth. Although you lose details in the data, it allows you to convey the message that you want the plot to show.
library(tidyverse)
x <- rep(seq(0, 3.2, 0.01), times = 100)
score <- rep(1:100, each = 321)
y = runif(32100) * score * 0.01
df <- tibble(x = x,
score = score,
y = y)
ggplot(data = df,
aes(x = x,
y = y,
group = score,
color = score))
geom_smooth(linewidth = 0.5, se = FALSE)
theme_bw()
theme(aspect.ratio = 0.5)
scale_color_gradient(low = 'blue', high = 'yellow')
CodePudding user response:
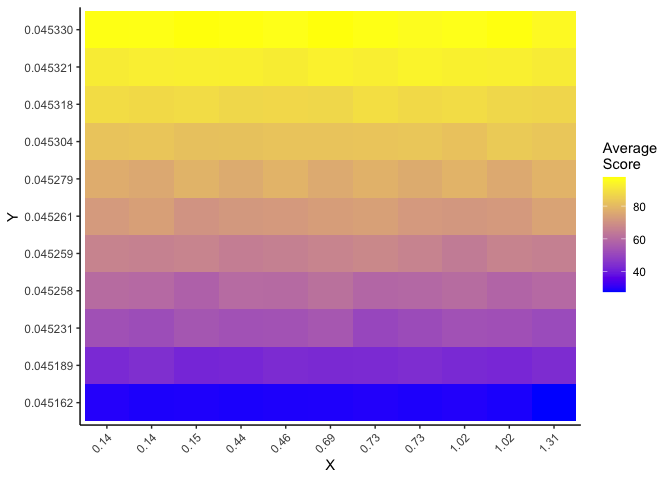
What about a heat map - which you could make by categorizing both x and y and then taking the average score in each x-y combination.
library(tidyverse)
x <- rep(seq(0, 3.2, 0.01), times = 100)
score <- rep(1:100, each = 321)
y = runif(32100) * score * 0.01
df <- tibble(x = x,
score = score,
y = y) %>%
mutate(x_cat = cut(x, breaks=11),
y_cat = cut(y, breaks=11)) %>%
group_by(x_cat, y_cat) %>%
summarise(score = mean(score),
x = median(range(x)),
y=median(range(y)))
#> `summarise()` has grouped output by 'x_cat'. You can override using the
#> `.groups` argument.
ggplot(df, aes(x=x_cat, y=y_cat, fill=score))
geom_tile()
scale_fill_gradient(low = 'blue', high = 'yellow')
scale_x_discrete(labels=sprintf("%.2f", sort(unique(df$x))))
scale_y_discrete(labels=sprintf("%.6f", sort(unique(df$y))))
theme_classic()
theme(axis.text.x = element_text(angle=45, hjust=1))
labs(x="X", y="Y", fill="Average\nScore")
Created on 2023-01-19 by the reprex package (v2.0.1)