If I have a dataframe
0 1 2
0 0.1 0.2 0.3
1 0.2 0.3 0.4
2 0.3 0.4 0.5
3 0.4 0.5 0.6
and I want to append it to my existing excel file, I will then write code
wb = load_workbook('test1.xlsx')
ws = wb['Sheet1']
for index, row in newdf.iterrows():
cell = 'D%d' % (index 2)
ws[cell] = row[0]
wb.save('test1.xlsx')
The problem with that code is, I only get the first column, since its iterating over the index. So for example this is excel sheet.
A B C D
1
2 0.1
3 0.2
4 0.3
5 0.4
How to make iteration until all the column finish with start at D2 cell ? I ve tried iteritems also it did not work.
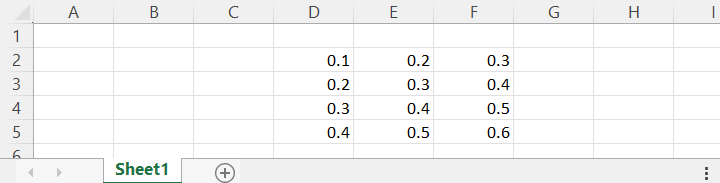
expected result should be
A B C D E F
1
2 0.1 0.2 0.3
3 0.2 0.3 0.4
4 0.3 0.4 0.5
5 0.4 0.5 0.6
CodePudding user response:
Here is a proposition based on your code :
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
wb = load_workbook("test1.xlsx")
ws = wb["Sheet1"]
for i, row in df.iterrows():
for j, value in enumerate(row):
r, c = i 2, get_column_letter(j 4)
cell_coordinates = f"{c}{r}"
ws[cell_coordinates] = value
wb.save("test1.xlsx")
There is also this