I have seen multiple answers on this topic but none answer exactly what I'm looking for : different colors for different columns in a dataframe
Here is a random dataframe which I color in the following way :
import numpy as np
import pandas as pd
example = [['test1',1,2,'',''],['test2',3,4,'',''],['test3','','',5,6],['test4','','',7,8]]
df = pd.DataFrame(example, columns=['column1','column2','column3','column4','column5'])
def highlight_col(x):
# if x == 0.0:
# blue 0= 'background-color: #ACE5EE '
blue = 'background-color: lightblue '
red = 'background-color: #ffcccb'
df = pd.DataFrame('', index=x.index, columns=x.columns)
df.iloc[:, 1:3] = blue #if x else 'white'
df.iloc[:, 3:6] = red #if x else 'white'
return df
df.style.apply(highlight_col,axis=None)

While this highlights the correct columns, I only want them colored when the cell is not blank thus have the two bottom rows of column2 and column3 white and the two top rows of column4 and column5 white like so :
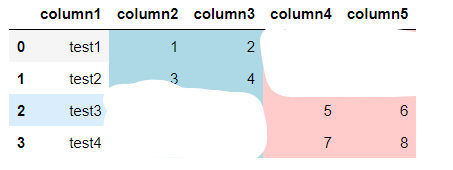
Please let me know if I'm not clear
CodePudding user response:
You can mask your output value using the original df, this solution is not very dynamic though:
def highlight_col(x):
# if x == 0.0:
# blue 0= 'background-color: #ACE5EE '
blue = 'background-color: lightblue '
red = 'background-color: #ffcccb'
df2 = pd.DataFrame('', index=x.index, columns=x.columns)
df2.iloc[:, 1:3] = blue #if x else 'white'
df2.iloc[:, 3:6] = red #if x else 'white'
return df2.where(df.ne(''))
df.style.apply(highlight_col, axis=None)
Output:
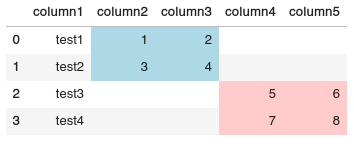
A more dynamic method:
colors = {'column2': 'lightblue', 'column3': 'lightblue',
'column4': '#ffcccb', 'column5': '#ffcccb'}
def highlight_col(s):
return s.mask(s.ne(''), f'background-color: {colors.get(s.name, "none")}')
df.style.apply(highlight_col, axis=0)