I have two data frames as below with some categories different. For example, DF1 has A, B categories which DF2 doesn't have. I coded as below to get individual data frames y_t2, y_t3.
DF1 <- data.frame(Firm1 = c("A", "B", "C", "L", "M", "L"))
DF2 <- data.frame(Firm2 = c("L", "M", "N", "P"))
library(dplyr)
y <- DF1 %>% group_by(Firm1) %>%
summarise(n = n())
y_t <- data.frame(t(y[,2:ncol(y)]))
colnames(y_t) <- data.frame(t(y[,1]))
y_t2 <- y_t
y_t2$dataframe <- c("Firm1")
y <- DF2 %>% group_by(Firm2) %>%
summarise(n = n())
y_t <- data.frame(t(y[,2:ncol(y)]))
colnames(y_t) <- data.frame(t(y[,1]))
y_t3 <- y_t
y_t3$dataframe <- c("Firm2")
I need to convert it into dummy variables for the categories of Group as below.
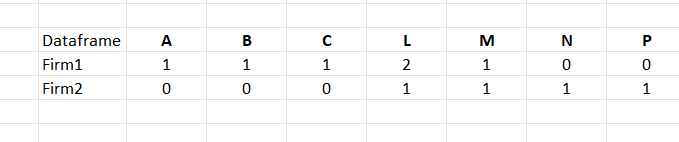
I checked links such as get the count and the price of category column then group by category but unable to progress using rbind.
Kindly advise how to code the logic to fetch the table. Thanks.
CodePudding user response:
t(table(do.call(rbind, lapply(list(DF1, DF2), stack))))
values
ind A B C L M N P
Firm1 1 1 1 2 1 0 0
Firm2 0 0 0 1 1 1 1
CodePudding user response:
I found a little longer way, not as great as @onyambu's suggestion.
y_t4 <- rbind.fill(y_t2, y_t3)
y_t4[is.na(y_t4)] <- 0