I've worked with Autoencoders for some weeks now, but I've seem to hit a rock wall when it comes to my understanding of losses overall. The issue I'm facing is that when trying to implement Batchnormalization & Dropout layers to my model, I get losses which aren't converging and awful reconstructions. A typical loss plot is something like this: 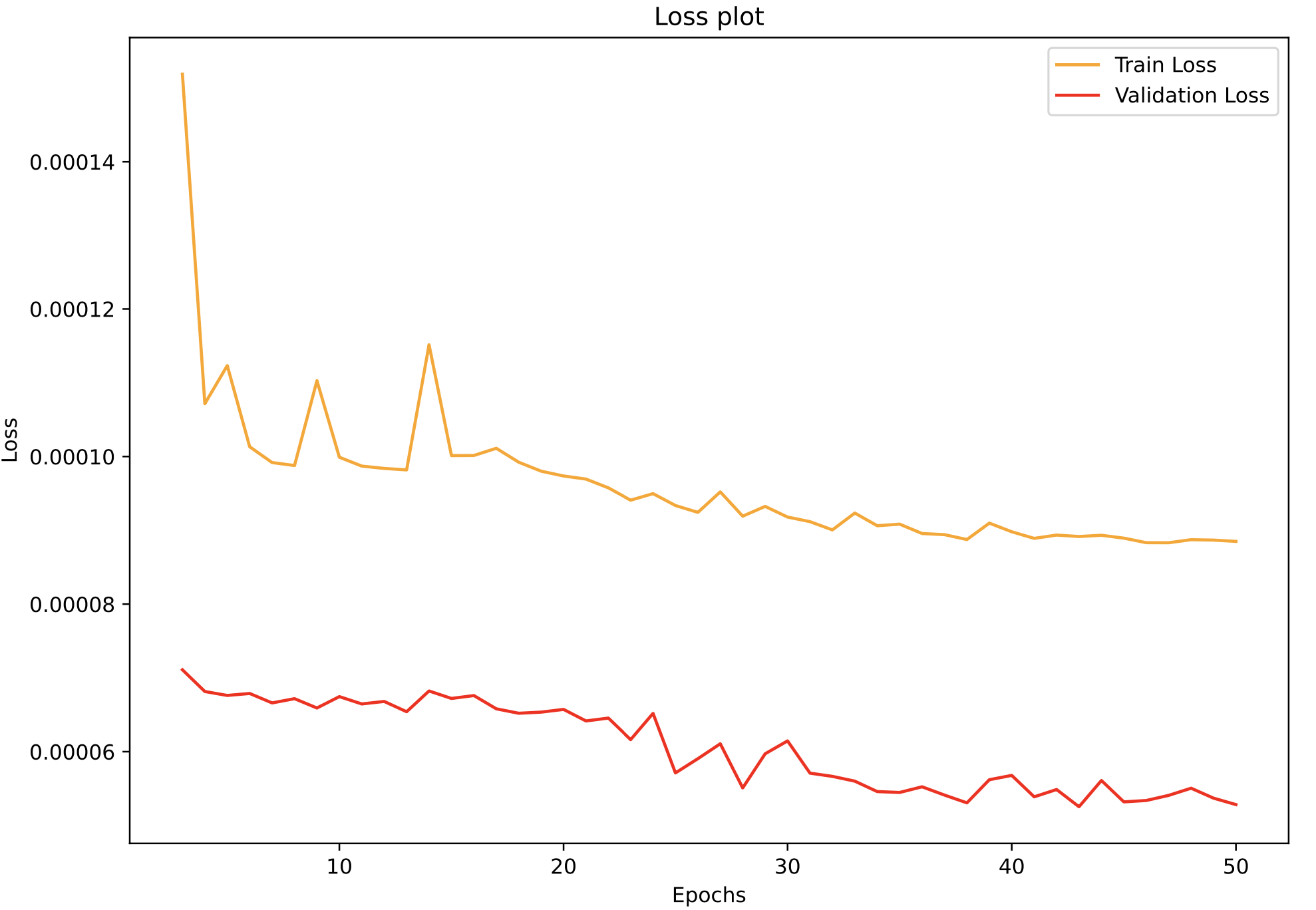 and the losses I use is an L1 regularization with MSE loss and looks something like this
and the losses I use is an L1 regularization with MSE loss and looks something like this
def L1_loss_fcn(model_children, true_data, reconstructed_data, reg_param=0.1, validate):
mse = nn.MSELoss()
mse_loss = mse(reconstructed_data, true_data)
l1_loss = 0
values = true_data
if validate == False:
for i in range(len(model_children)):
values = F.relu((model_children[i](values)))
l1_loss = torch.sum(torch.abs(values))
loss = mse_loss reg_param * l1_loss
return loss, mse_loss, l1_loss
else:
return mse_loss
with my training loop written as:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
train_run_loss = 0
val_run_loss = 0
for epoch in range(epochs):
print(f"Epoch {epoch 1} of {epochs}")
# TRAINING
model.train()
for data in tqdm(train_dl):
x, _ = data
reconstructions = model(x)
optimizer.zero_grad()
train_loss, mse_loss, l1_loss =L1_loss_fcn(model_children=model_children, true_data=x,reg_param=regular_param, reconstructed_data=reconstructions, validate=False)
train_loss.backward()
optimizer.step()
train_run_loss = train_loss.item()
# VALIDATING
model.eval()
with torch.no_grad():
for data in tqdm(test_dl):
x, _ = data
reconstructions = model(x)
val_loss = L1_loss_fcn(model_children=model_children, true_data=x, reg_param=regular_param, reconstructed_data = reconstructions, validate = True)
val_run_loss = val_loss.item()
epoch_loss_train = train_run_loss / len(train_dl)
epoch_loss_val = val_run_loss / len(test_dl)
where I've tried different hyper-parameter values without luck. My model looks something like this,
encoder = nn.Sequential(nn.Linear(), nn.Dropout(p=0.5), nn.LeakyReLU(), nn.BatchNorm1d(),
nn.Linear(), nn.Dropout(p=0.4), nn.LeakyReLU(), nn.BatchNorm1d(),
nn.Linear(), nn.Dropout(p=0.3), nn.LeakyReLU(), nn.BatchNorm1d(),
nn.Linear(), nn.Dropout(p=0.2), nn.LeakyReLU(), nn.BatchNorm1d(),
)
decoder = nn.Sequential(nn.Linear(), nn.Dropout(p=0.2), nn.LeakyReLU(),
nn.Linear(), nn.Dropout(p=0.3), nn.LeakyReLU(),
nn.Linear(), nn.Dropout(p=0.4), nn.LeakyReLU(),
nn.Linear(), nn.Dropout(p=0.5), nn.ReLU(),
)
What I expect to find is a converging train & validation loss, and thereby a lot better reconstructions overall, but I think that I'm missing something quite grave I'm afraid. Some help would be greatly appreciated!
CodePudding user response:
You are not comparing apples to apples, your code reads
l1_loss = 0
values = true_data
if validate == False:
for i in range(len(model_children)):
values = F.relu((model_children[i](values)))
l1_loss = torch.sum(torch.abs(values))
loss = mse_loss reg_param * l1_loss
return loss, mse_loss, l1_loss
else:
return mse_loss
So your validation loss is just MSE, but training is MSE regularization, so obviously your train loss will be higher. You should log just train MSE without regulariser if you want to compare them.
Also, do not start with regularisation, always start witha model with no regularisation at all and get training to converge. Remove all extra losses, remove your dropouts. These things only harm your ability to learn (but might improve generalisation). Once this is achieved - reintroduce them one at a time.