I have an output table I've created that includes customer level information and some more granular data (plan level information) as well, such that clients information may repeat in the data. Here is a simplified example:
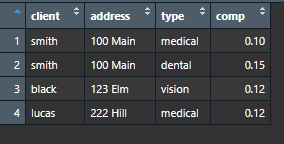
client <- c('smith', 'smith', 'black', 'lucas')
address <- c('100 Main', '100 Main', '123 Elm', '222 Hill')
type <- c('medical', 'dental', 'vision', 'medical')
comp <- c(.1, .15, .12, .12)
sample <- bind_cols(client = client, address = address, type `= type, comp = comp)`
How can I use pivot_wider(), or another dplyr function to transform data such that each row is a client and each plan level field appears as a new column. Output would be like this:
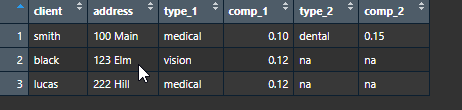
client <- c('smith', 'black', 'lucas')
address <- c('100 Main', '123 Elm', '222 Hill')
type_1 <- c('medical', 'vision', 'medical')
comp_1 <- c(.1, .12, .12)
type_2 <- c('dental', 'na', 'na')
comp_2 <- c(.15, 'na','na')
sample_final <- bind_cols(client = client, address = address
, type_1 = type_1, comp_1 = comp_1
, type_2 = type_2, comp_2 = comp_2)
CodePudding user response:
First create row numbers within each client, then pass the row numbers to names_from in pivot_wider(). Also note use of names_vary = "slowest" to get your columns in the desired order.
library(dplyr)
library(tidyr)
sample %>%
group_by(client) %>%
mutate(num = row_number()) %>%
ungroup() %>%
pivot_wider(
names_from = num,
values_from = type:comp,
names_vary = "slowest"
)
# A tibble: 3 × 6
client address type_1 comp_1 type_2 comp_2
<chr> <chr> <chr> <dbl> <chr> <dbl>
1 smith 100 Main medical 0.1 dental 0.15
2 black 123 Elm vision 0.12 <NA> NA
3 lucas 222 Hill medical 0.12 <NA> NA