I have Pandas DataFrame like below:
Input data:
- Y - binnary target
- X1...X5 - predictors
Source code of DataFrame:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
from xgboost import XGBClassifier
df = pd.DataFrame()
df["Y"] = [1,0,1,0]
df["X1"] = [111,12,150,270]
df["X2"] = [22,33,44,55]
df["X3"] = [1,1,0,0]
df["X4"] = [0,0,0,1]
df["X5"] = [150, 222,230,500]
Y | X1 | X2 | X3 | X4 | X5
----|-----|-----|-------|-------|-----
1 | 111 | 22 | 1 | 0 | 150
0 | 12 | 33 | 1 | 0 | 222
1 | 150 | 44 | 0 | 0 | 230
0 | 270 | 55 | 0 | 1 | 500
My code: -> I Run XGBClassifier() model, where in each successive iteration of the loop one variable is removed So, each successive model is built with 1 less variable than the previous one, the last model in the iteration is built with only 1 predictor
X_train, X_test, y_train, y_test = train_test_split(df.drop("Y", axis=1)
, df.Y
, train_size = 0.70
, test_size=0.30
, random_state=1
, stratify = df.Y)
results = []
list_of_models = []
Num_var_in = []
predictors = X_train.columns.tolist()
Var_out = []
for i in X_train.columns:
#model building
model = XGBClassifier()
model.fit(X_train, y_train)
list_of_models.append(model)
#evaluation
results.append({"AUC_train": round(metrics.roc_auc_score(y_train, model.predict_proba(X_train)[:,1]), 5),
"AUC_test": round(metrics.roc_auc_score(y_test, model.predict_proba(X_test)[:,1]), 5),})
#Num_var_in - number of predictors which was used to create model during that iteration
Num_var_in.append(len(X_train.columns.tolist()))
#Var_out - name of variable which was removed during that iteration
if sorted(predictors) == sorted(X_train.columns.tolist()):
Var_out.append(np.nan)
else:
Var_out.append(set(predictors) - set(X_train.columns.tolist()))
#drop 1 predictor after each loop iteration
X_train = X_train.drop(i, axis=1)
X_test = X_test.drop(i, axis=1)
#save results to DataFrame
results = pd.DataFrame(results)
results["Num_var_in"] = Num_var_in
results["Var_out"] = Var_out
results.reset_index(inplace = True)
results.rename(columns = {"index":"Model"}, inplace = True)
results
Current output:
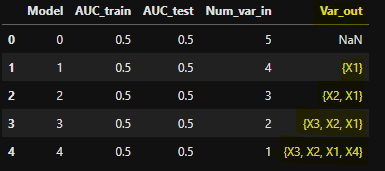
Requirements:
- In output in column "Var_out" I need to have one variable that has been discarded in a given iteration, not all that have been discarded so far
Desire output:
Model | AUC_train | AUC_test | Num_var_in | Var_out
------|------------|------------|-------------|---------
0 | 0.5 | 0.5 | 5 | NaN
1 | 0.5 | 0.5 | 4 | X1
2 | 0.5 | 0.5 | 3 | X2
3 | 0.5 | 0.5 | 2 | X3
4 | 0.5 | 0.5 | 1 | X4
How can I modify my code in Python so as to have output in Var_out like in "Desire output" ?
CodePudding user response:
You can use: (check # HERE comments)
results = []
list_of_models = []
Num_var_in = []
predictors = X_train.columns.tolist()
Var_out = [np.nan] # HERE (init with nan)
for i in X_train.columns:
#model building
model = XGBClassifier()
model.fit(X_train, y_train)
list_of_models.append(model)
#evaluation
results.append({"AUC_train": round(metrics.roc_auc_score(y_train, model.predict_proba(X_train)[:,1]), 5),
"AUC_test": round(metrics.roc_auc_score(y_test, model.predict_proba(X_test)[:,1]), 5),})
#Num_var_in - number of predictors which was used to create model during that iteration
Num_var_in.append(len(X_train.columns.tolist()))
#Var_out - name of variable which was removed during that iteration
Var_out.append(i) # HERE (just append the current column)
#drop 1 predictor after each loop iteration
X_train = X_train.drop(i, axis=1)
X_test = X_test.drop(i, axis=1)
#save results to DataFrame
results = pd.DataFrame(results)
results["Num_var_in"] = Num_var_in
results["Var_out"] = Var_out[:-1] # HERE (remove the last value)
results.reset_index(inplace = True)
results.rename(columns = {"index":"Model"}, inplace = True)
Output:
>>> results
Model AUC_train AUC_test Num_var_in Var_out
0 0 1.00000 0.98270 5 NaN
1 1 1.00000 0.98590 4 X1
2 2 1.00000 0.97790 3 X2
3 3 0.99981 0.97075 2 X3
4 4 0.92516 0.59971 1 X4
Minimal reproducible example:
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=1000, n_features=5, n_classes=2, random_state=2023)
df = pd.DataFrame(X, columns=[f'X{i}' for i in range(1, X.shape[1] 1)])
df = pd.concat([pd.Series(y, name='Y'), df], axis=1)
X_train, X_test, y_train, y_test = \
train_test_split(df.iloc[:, 1:], df['Y'], test_size=0.2, random_state=2023)