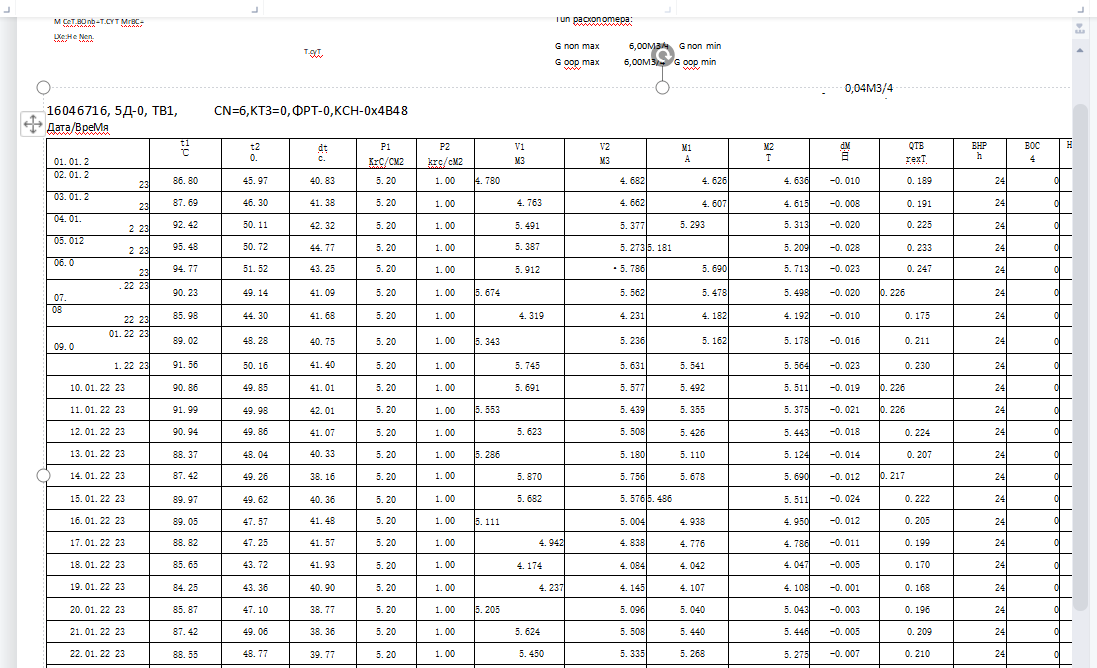
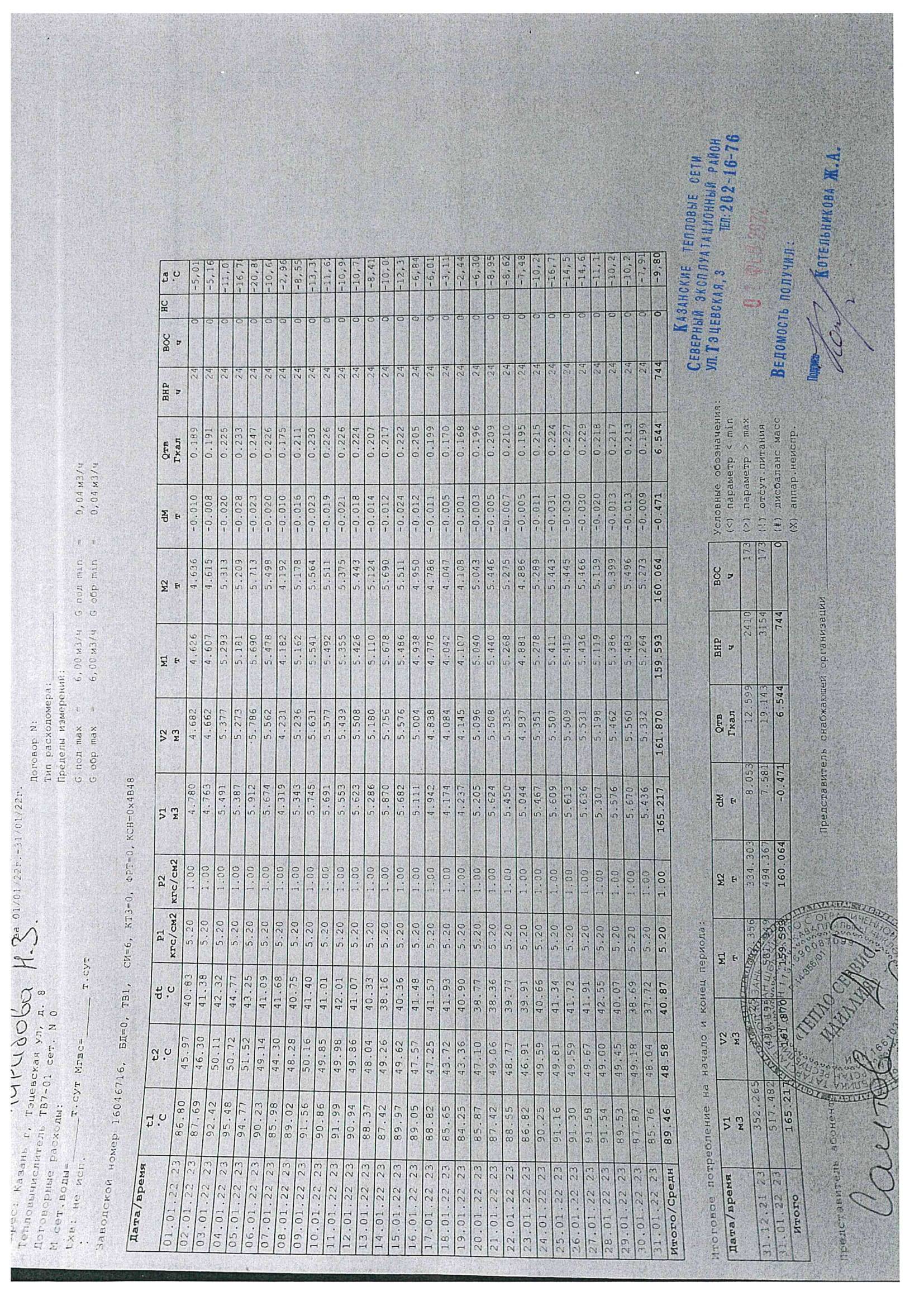
 I need to convert a lot PDF tables data scans with bad quality to excel tables. The only way I see the solution is to train tesseract or some other framework on pre-generated images(all tables in PDF are the same in most cases). Is it real to have a great solution around 70-80% at home conditions and what you can advice. I will appreciate any advice other than Abby FineReader or similar solution(tested on my dataset - result is so bad and few opportunities for automation)
I need to convert a lot PDF tables data scans with bad quality to excel tables. The only way I see the solution is to train tesseract or some other framework on pre-generated images(all tables in PDF are the same in most cases). Is it real to have a great solution around 70-80% at home conditions and what you can advice. I will appreciate any advice other than Abby FineReader or similar solution(tested on my dataset - result is so bad and few opportunities for automation)
All tables structures need to be correct in result for further handwork.
CodePudding user response:
When the input image is a very poor quality the dirt tends to get in the way of text recognition. This is exacerbated when trying to look for areas without dictionary entries, thus only numbers can be the worst type of text to train, for every twist and turn that bad scanning produces.
If the electronic source before manual stamp and scan is available it might be possible to meld the text with the distorted image , but its a highly manual task defeating the aim.
The docents need to be rescanned, by a trained operator, with a good eye for details. That, with an OCR scan device, will be faster than tuning images that are never likely to provide a reasonably trustworthy output. There are too many cases of numeric fails, that would make any single page worthless for reading or computations.
Recently scanned some accounts and spent more time check/correct than if it had been typed, but it needed to be "legal" copy, however clearly it was not as I did it after the event.
The best result I could squeeze from Adobe PDF to Excel was "Pants"
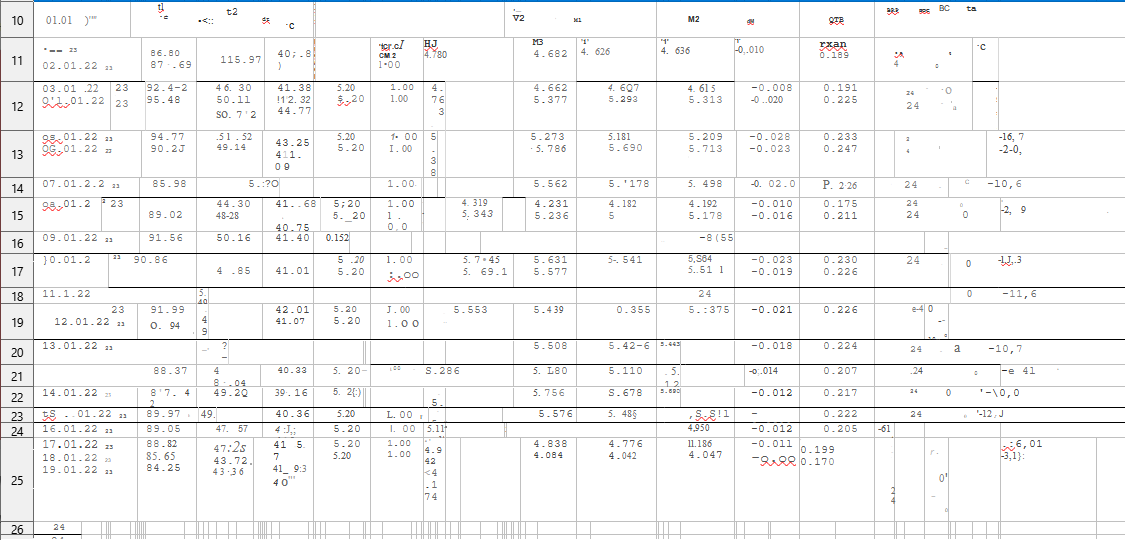
CodePudding user response:
There are some improvements in image contrast and noise reduction (handwork).
Some effect but not obvious.
Image2word