I have a dataframe given as such:
#Load the required libraries
import pandas as pd
#Create dataset
data = {'id': ['A', 'A', 'A', 'A', 'A','A', 'A',
'B', 'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C',
'D', 'D', 'D', 'D',
'E', 'E', 'E', 'E', 'E','E'],
'cycle': [1,2, 3, 4, 5,6,7,
1,2, 3,4,5,6,
1,2, 3, 4, 5,
1,2, 3, 4,
1,2, 3, 4, 5,6,],
'Salary': [7, 7, 7,8,9,10,15,
4, 4, 4,4,5,6,
8,9,10,12,13,
8,9,10,11,
7, 11,12,13,14,15,],
'Jobs': [123, 18, 69, 65, 120, 11, 52,
96, 120,10, 141, 52,6,
101,99, 128, 1, 141,
141,123, 12, 66,
12, 128, 66, 100, 141, 52,],
'Days': [123, 128, 66, 66, 120, 141, 52,
96, 120,120, 141, 52,96,
15,123, 128, 120, 141,
141,123, 128, 66,
123, 128, 66, 120, 141, 52,],
}
#Convert to dataframe
df = pd.DataFrame(data)
print("df = \n", df)
The above dataframe looks as such:
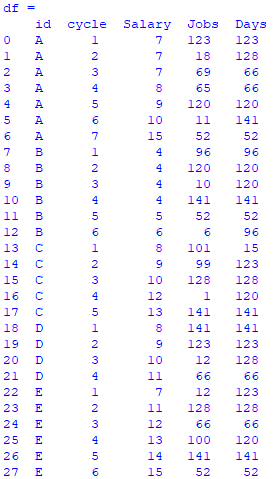
Here, I wish to apply 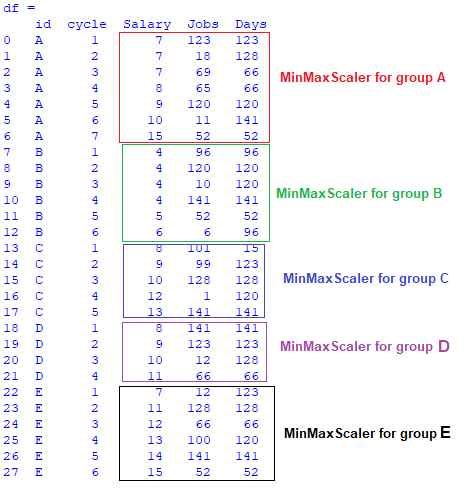
Can somebody please let me know how to achieve this task in Python?
CodePudding user response:
You can use groupby to compute minmax scale per group:
cols = ['Salary', 'Jobs', 'Days']
minmax_scale = lambda x: (x - x.min(axis=0)) / (x.max(axis=0) - x.min(axis=0))
df[cols] = df.groupby('id')[cols].apply(minmax_scale)
Output:
>>> df
id cycle Salary Jobs Days
0 A 1 0.000000 1.000000 0.797753
1 A 2 0.000000 0.062500 0.853933
2 A 3 0.000000 0.517857 0.157303
3 A 4 0.125000 0.482143 0.157303
4 A 5 0.250000 0.973214 0.764045
5 A 6 0.375000 0.000000 1.000000 # Max for Days of Group A
6 A 7 1.000000 0.366071 0.000000 # Min for Days of Group A
7 B 1 0.000000 0.666667 0.494382
8 B 2 0.000000 0.844444 0.764045
9 B 3 0.000000 0.029630 0.764045
10 B 4 0.000000 1.000000 1.000000
11 B 5 0.500000 0.340741 0.000000
12 B 6 1.000000 0.000000 0.494382
13 C 1 0.000000 0.714286 0.000000
14 C 2 0.200000 0.700000 0.857143
15 C 3 0.400000 0.907143 0.896825
16 C 4 0.800000 0.000000 0.833333
17 C 5 1.000000 1.000000 1.000000
18 D 1 0.000000 1.000000 1.000000
19 D 2 0.333333 0.860465 0.760000
20 D 3 0.666667 0.000000 0.826667
21 D 4 1.000000 0.418605 0.000000
22 E 1 0.000000 0.000000 0.797753
23 E 2 0.500000 0.899225 0.853933
24 E 3 0.625000 0.418605 0.157303
25 E 4 0.750000 0.682171 0.764045
26 E 5 0.875000 1.000000 1.000000
27 E 6 1.000000 0.310078 0.000000
As suggested by @mozway, you can use a function or the walrus operator in lambda function:
# The fastest
def minmax_scale(x):
xmin = x.min(axis=0)
xmax = x.max(axis=0)
return (x - xmin) / (xmax - xmin)
# Average performance, using walrus operator (Python >= 3.8)
minmax_scale = lambda x: (x - (m := x.min(axis=0))) / (x.max(axis=0) - m)
# The slowest
minmax_scale = lambda x: (x - x.min(axis=0)) / (x.max(axis=0) - x.min(axis=0))