I have a dataframe given as such:
#Load the required libraries
import pandas as pd
#Create dataset
data = {'id': ['A', 'A', 'A', 'A', 'A','A', 'A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C', 'C',
'D', 'D', 'D', 'D',
'E', 'E', 'E', 'E', 'E','E', 'E', 'E','E'],
'cycle': [1,2, 3, 4, 5,6,7,8,9,10,11,
1,2, 3,4,5,6,
1,2, 3, 4, 5,6,
1,2, 3, 4,
1,2, 3, 4, 5,6,7,8,9,],
'Salary': [7, 7, 7,8,9,10,11,12,13,14,15,
4, 4, 4,4,5,6,
8,9,10,11,12,13,
8,9,10,11,
7, 7,9,10,11,12,13,14,15,],
'Children': ['No', 'Yes', 'Yes', 'Yes', 'Yes', 'No','No', 'Yes', 'Yes', 'Yes', 'No',
'Yes', 'Yes', 'No', 'Yes', 'Yes', 'Yes',
'No','Yes', 'Yes', 'No','No', 'Yes',
'Yes', 'No','Yes', 'Yes',
'No', 'Yes', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'No',],
'Days': [123, 128, 66, 66, 120, 141, 52,96, 120, 141, 52,
96, 120,120, 141, 52,96,
15,123, 128, 66, 120, 141,
141,123, 128, 66,
123, 128, 66, 123, 128, 66, 120, 141, 52,],
}
#Convert to dataframe
df = pd.DataFrame(data)
print("df = \n", df)
The above dataframe looks as such:
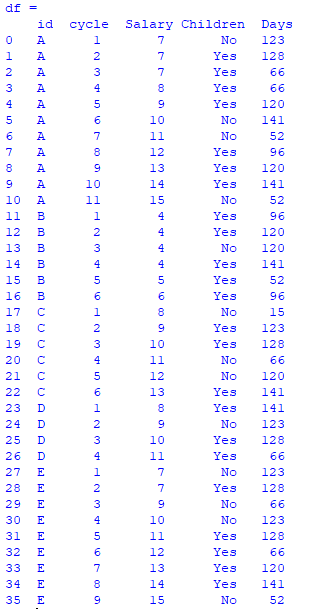
Here,
id 'A' as 11 cycle
id 'B' as 6 cycle
id 'C' as 6 cycle
id 'D' as 4 cycle
id 'E' as 9 cycle
I need to regroup the dataframe based on following two cases:
Case 1: Increasing order of the cycle
The datafrmae needs to be arraged in the increasing order of the cycle.
i.e. D(4 cycle) comes first, then B(6 cycle), C(6 cycle), E(9 cycle), A(11 cycle)
The dataframe need to look as such:
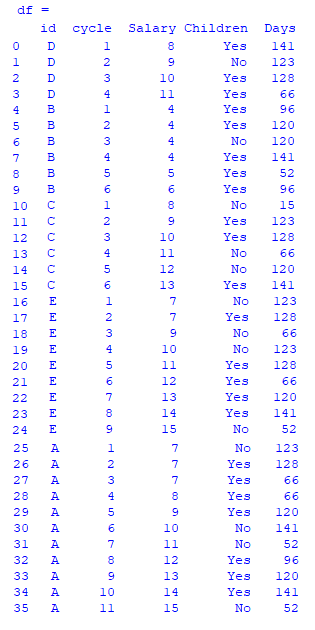
Case 2: Decreasing order of the cycle
The datafrmae needs to be arraged in the decreasing order of the cycle.
i.e. A(11 cycle) comes first, then E(9 cycle), B(6 cycle), C(6 cycle), D(4 cycle)
The dataframe need to look as such:
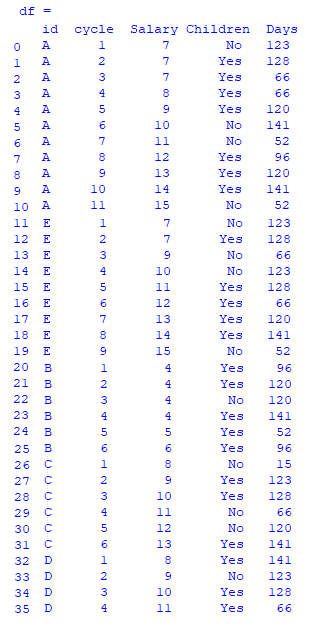
In both the cases, id 'B' and 'C' has 6 cycle. So it is immaterial which will come first amongst 'B' and 'C'.
Also, the index number dosen't change in the original and regrouped cases.
Can somebody please let me know hot to achieve this task in Python?
CodePudding user response:
Use groupby.transform('size') as the sorting value:
Either using a temporary column:
(df.assign(size=df.groupby('id')['cycle'].transform('size'))
.sort_values(by=['size', 'id'], kind='stable',
# ascending=False # uncomment for descending order
)
.drop(columns='size')
)
Or, passing as key to sort_values:
df.sort_values(by='id', key=lambda x: df.groupby(x)['cycle'].transform('size'),
kind='stable')
Output:
id cycle Salary Children Days
23 D 1 8 Yes 141
24 D 2 9 No 123
25 D 3 10 Yes 128
26 D 4 11 Yes 66
11 B 1 4 Yes 96
12 B 2 4 Yes 120
13 B 3 4 No 120
14 B 4 4 Yes 141
15 B 5 5 Yes 52
16 B 6 6 Yes 96
17 C 1 8 No 15
18 C 2 9 Yes 123
19 C 3 10 Yes 128
20 C 4 11 No 66
21 C 5 12 No 120
22 C 6 13 Yes 141
27 E 1 7 No 123
28 E 2 7 Yes 128
29 E 3 9 No 66
30 E 4 10 No 123
31 E 5 11 Yes 128
32 E 6 12 Yes 66
33 E 7 13 Yes 120
34 E 8 14 Yes 141
35 E 9 15 No 52
0 A 1 7 No 123
1 A 2 7 Yes 128
2 A 3 7 Yes 66
3 A 4 8 Yes 66
4 A 5 9 Yes 120
5 A 6 10 No 141
6 A 7 11 No 52
7 A 8 12 Yes 96
8 A 9 13 Yes 120
9 A 10 14 Yes 141
10 A 11 15 No 52
CodePudding user response:
col1=df.groupby("id").cycle.transform("max")
case1=df.assign(col1=col1).sort_values(['col1','id'])
case1
case2=df.assign(col1=col1).sort_values(['col1','id'],ascending=False)
case2