Here is my dataframe:
df
year 2022 2021
0 return on equity (roe) 160.90% 144.10%
1 average equity 62027.9677 65704.372
2 net profit margin 0.2531 0.2588
3 turnover 1.1179 1.0422
4 leverage 5.687 5.3421
I want to write it into excel without index:
df.to_excel('/tmp/test.xlsx',index=False)
Why there is a empty cell at the left-up corner in the test.xlsx file?
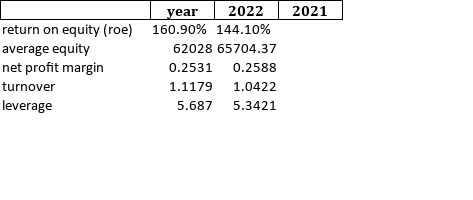
How can get the below format with to_excel method?
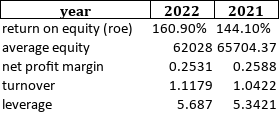
It is no use to add header argument.
df.to_excel('/tmp/test.xlsx', index=False, header=True)
Now read from the excel:
new_df = pd.read_excel('/tmp/test.xlsx',index_col=False)
new_df
Unnamed: 0 year 2022 2021
0 return on equity (roe) 160.90% 144.10% NaN
1 average equity 62027.9677 65704.372 NaN
2 net profit margin 0.2531 0.2588 NaN
3 turnover 1.1179 1.0422 NaN
4 leverage 5.687 5.3421 NaN
Can't add header argument when reading:
new_df = pd.read_excel('/tmp/test.xlsx',index_col=False,header=True)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/debian/.local/lib/python3.9/site-packages/pandas/util/_decorators.py", line 211, in wrapper
return func(*args, **kwargs)
File "/home/debian/.local/lib/python3.9/site-packages/pandas/util/_decorators.py", line 331, in wrapper
return func(*args, **kwargs)
File "/home/debian/.local/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 490, in read_excel
data = io.parse(
File "/home/debian/.local/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 1734, in parse
return self._reader.parse(
File "/home/debian/.local/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 732, in parse
validate_header_arg(header)
File "/home/debian/.local/lib/python3.9/site-packages/pandas/io/common.py", line 203, in validate_header_arg
raise TypeError(
TypeError: Passing a bool to header is invalid. Use header=None for no header or header=int or list-like of ints to specify the row(s) making up the column names
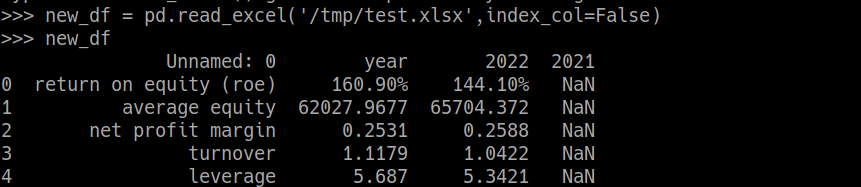
CodePudding user response:
Include the header parameter as true:
df.to_excel('test.xlsx', index=False, header=True)
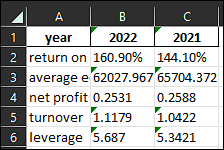
Back to a df, set index_col parameter to none:
new_df = pd.read_excel('test.xlsx',index_col=None)
print(new_df)
year 2022 2021
0 return on equity (roe) 160.90% 144.10%
1 average equity 62027.9677 65704.372
2 net profit margin 0.2531 0.2588
3 turnover 1.1179 1.0422
4 leverage 5.687 5.3421
CodePudding user response:
I find the reason,the dataframe for the example is special:
df.columns
MultiIndex([('year',),
('2022',),
('2021',)],
)
It's not a single index.
df.columns = ['year', '2022', '2021']
df.to_excel('/tmp/test.txt',index=False)
The strange phenomenon disappeared at last.
dataframe with multiIndex [('year',),('2022',),('2021',)] display the same appearance such as single index ['year', '2022', '2021'] in my case.