I'm trying to fill empty cells from a single column (and then from multiple columns) using the standard deviation. I have seen several explanations but so far haven't seen any that is straightforward and pertinent to this question. Thank you in advance for your time!
Here is what I have so far:
To obtain random values, I first calculated the mean for the Math column:
filename = os.path.join(os.path.dirname(__file__),'exam.csv')
data = pd.read_csv(filename)
math_mean = data['Math'].mean()
print(math_mean)
The output of that is 73.625
Then, I calculated the Standard deviation:
math_std = data['Math'].std()
print(math_std)
Which gave me 10.14097064951308 for STD.
73-10 = 63
73 10 = 83
Based on the calculation above, I need to generate random values between 63 and 83 and fill in the empty cells of the Math column. I used np.random.randint() to get the random values:
random_grades = np.random.randint(63,83)
print(random_grades)
So everything is fine so far, and the random values do get inserted into the empty cells. However, it's the same value repeating over and over.
I'm using this syntax:
#Producing random age values
random_grades = np.random.randint(63.48, 83.76)
print(random_grades)
#Storing new random ages to variable
new_grades = data.Math.fillna(random_grades)
print(new_grades)
#Passing new values to table
data['Math'].fillna(new_grades,inplace=True)
print(data)
This is the output:
0 79.0
1 82.0
2 85.0
3 77.0 # random value
4 70.0
5 77.0 # same random value
6 84.0
7 67.0
8 77.0 # same random value
9 63.0
10 59.0
If I try to add the parameter size= in random_grades = np.random.randint(63.48, 83.76, size=5) I get an error:
Traceback (most recent call last):
File "c:/Users/Desktop/tiny.py", line 88, in <module>
new_grades = data.Math.fillna(random_grades)
File "C:\Users\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\site-packages\pandas\core\series.py", line 4433, in fillna
return super().fillna(
File "C:\Users\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\site-packages\pandas\core\generic.py", line 6397, in fillna
raise TypeError(
TypeError: "value" parameter must be a scalar, dict or Series, but you passed a "ndarray"
What am I missing?
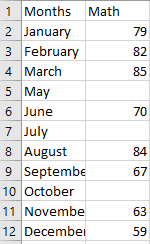
CodePudding user response:
First idea is test missing values and assign length of random values count by number (by sum with True = 1 and False = 0) of missing values by N parameter in numpy.random.randint:
mean = data['Math'].mean()
std = data['Math'].std()
mask = data['Math'].isna()
data.loc[mask, 'Math'] = np.random.randint(mean - std, mean std, mask.sum())
Your solution is similar, only is converted numpy array to Series with index for missing values:
mean = data['Math'].mean()
std = data['Math'].std()
#Testing missing values
mask = data['Math'].isna()
#Producing random age values
random_grades = np.random.randint(mean - std, mean std, mask.sum())
print(random_grades)
#convert array to Series and replace missing values
data['Math'] = data.Math.fillna(pd.Series(random_grades, index=data.index[mask]))
print(data)
CodePudding user response:
Try using apply for different values
df.Math = df.Math.apply(lambda x: np.random.randint(63.48, 83.76) if pd.isna(x) else x)
CodePudding user response:
np.random.randint(63.48, 83.76)
generates a single value, whereas-
np.random.randint(63.48, 83.76, 5)
generates 5 random values within the limits specified.