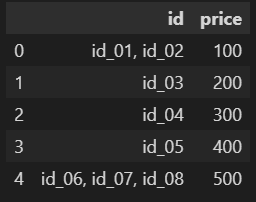
I have a data frame like this:
data = {'id': ['id_01, id_02',
'id_03',
'id_04',
'id_05',
'id_06, id_07, id_08'],
'price': [100, 200, 300, 400, 500]}
df = pd.DataFrame(data)
df
output:
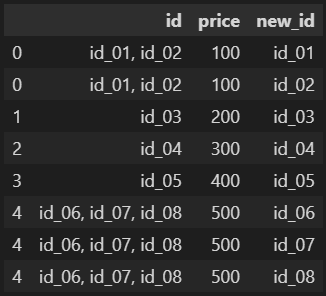
I did this to split each id and analyse each as single row:
new_df = df.assign(new_id=df.id.str.split(",")).explode('new_id')
new_df
output:
So far, so good =) Now I'd like to reach this result below, where I calculate each price divided by the lenght of id items in each row, like this:
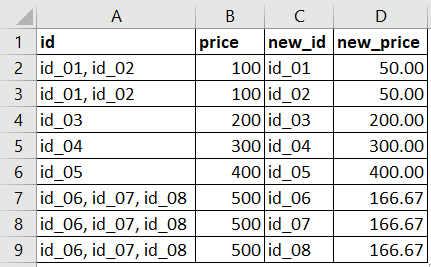
How can I reach this result using the most simple way for a beginner student?
CodePudding user response:
Calculate this before you explode when you can access the length of id items via .str.len():
(df.assign(new_id=df.id.str.split(","))
.assign(new_price=lambda df: df.price / df.new_id.str.len())
.explode('new_id'))
id price new_id new_price
0 id_01, id_02 100 id_01 50.000000
0 id_01, id_02 100 id_02 50.000000
1 id_03 200 id_03 200.000000
2 id_04 300 id_04 300.000000
3 id_05 400 id_05 400.000000
4 id_06, id_07, id_08 500 id_06 166.666667
4 id_06, id_07, id_08 500 id_07 166.666667
4 id_06, id_07, id_08 500 id_08 166.666667
CodePudding user response:
Another way and in one line, str. split into a column, find the len of new list and use it to find average on dynamically. Faster than a lambda.
new_df = (df.assign(new_id=df.id.str.split(","),#new colume
price=df['price'].div(df.id.str.split(",").str.len())#Find average
.astype(int)).explode('new_id')#Explode to expnd the df
)
output
id price new_id
0 id_01, id_02 50 id_01
0 id_01, id_02 50 id_02
1 id_03 200 id_03
2 id_04 300 id_04
3 id_05 400 id_05
4 id_06, id_07, id_08 166 id_06
4 id_06, id_07, id_08 166 id_07
4 id_06, id_07, id_08 166 id_08
CodePudding user response:
Probably not the best solution, but you can use the fact that exploded rows have the same index:
new_df['new_price'] = new_df['price']/new_df.groupby(new_df.index).transform('count')['id']