I have a PDF file that contains Timetable of a university, generated from aSc Timetables software.
The data looks something like this,
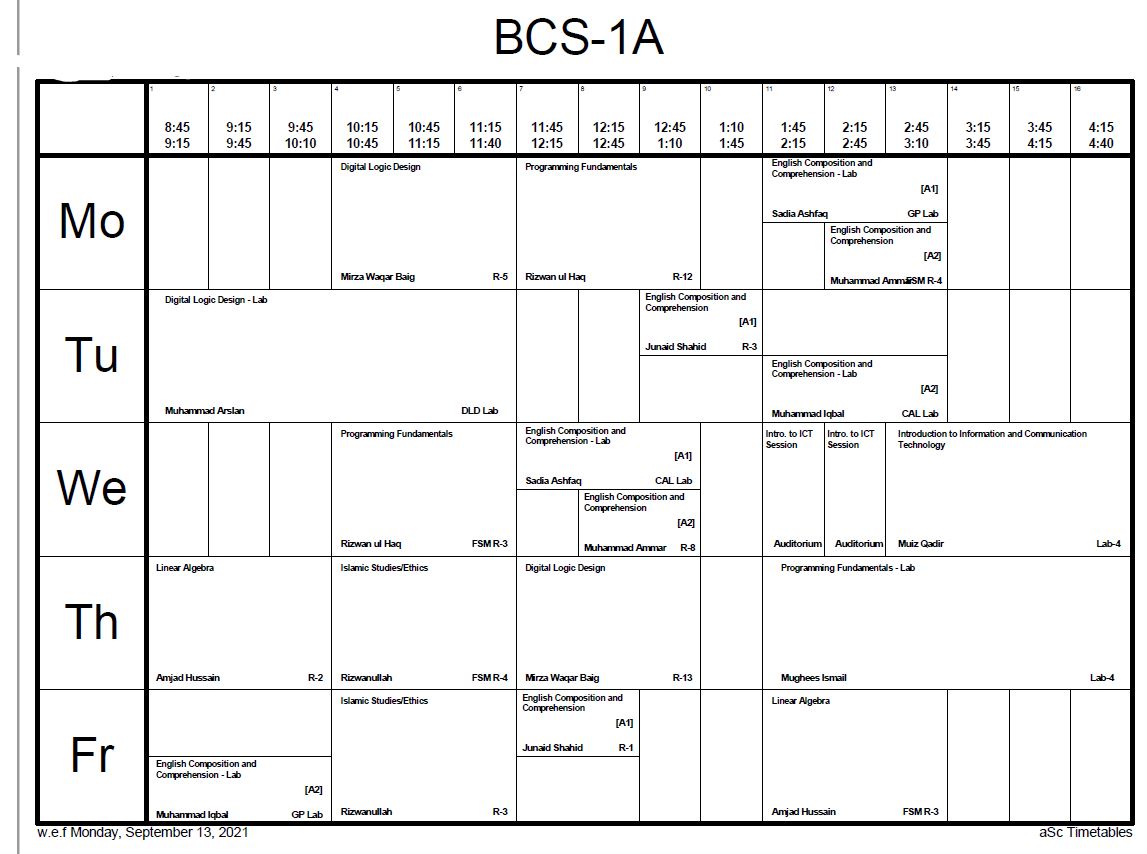
There are about 29 such pages in the PDF file.
I want to process this data for a program and therefore, want it to be in readable form in any programming language, and preferably in C or in Python language.
Can anyone guide me how could I do it? Maybe some library that I can use to convert this data into a Text file using C ?
What I need the data to be in is in this kind of form,
Suppose in C , we have a class with the name of Section (one object will represent each section, for example "BCS-1A"'s object or "BCS-7E" object and etc.)
So, for BCS-1A
Section Object:
section_name: "BCS-1A" // (section_name is a string data member)
// There will be 7 arrays, each representing one day of the week and each array will be of size 16. One index of the array will represent one time slot of that day. So, in this case,
moday_schedule[16]; // it will be an **linked list** array of 16 size. Each index can be empty or may contain as many slots as possible. Each index represents the time slot in the timetable. For example "0th" index will represent the time slot of 8:45 to 9:15, 16th index will represent 4:15 to 4:40 and etc.
// For example, monday_schedule[0] will be EMPTY.
// monday_schedule[4] will contain an object that will have following information,
// Subject: Digital Logic Design
// Teacher: Mirza Waqar Baig
// Sub-section: None (there is a sub-section in some lectures)
// Room: R-5
// monday_schedule[5] will also contain same information
// monday_schedule[12] will have two objects.
// and both the objects will have an attribute of "Sub-section" as well
CodePudding user response:
I've compiled up a repository on GitHub
I used pdf2image to first convert the pdf to image files and store those files in an images folder.
Then used pytesseract to convert those images to txt files and store those txt files in texts folder.
After that, I formatted the text a little and store it in csv format in csvs folder.