I have a weird performance which I can not explain. During the training of my network, and after I am done with the calculation of my training batch, I directly go as well over the validation set and take a batch and test my model on it. So, my validation is not done on a different step from the training. But I just run a batch of the training then as well a batch of a validation.
My code looks similar to that:
for (data, targets) in tqdm(training_loader):
output = net(data)
log_p_y = log_softmax_fn(output)
loss = loss_fn(log_p_y, targets)
# Do backpropagation
val_data = itertools.cycle(val_loader)
valdata, valtargets = next(val_data)
val_output = net(valdata)
log_p_yval = log_softmax_fn(val_output)
loss_val = loss_fn(log_p_yval, valtargets)
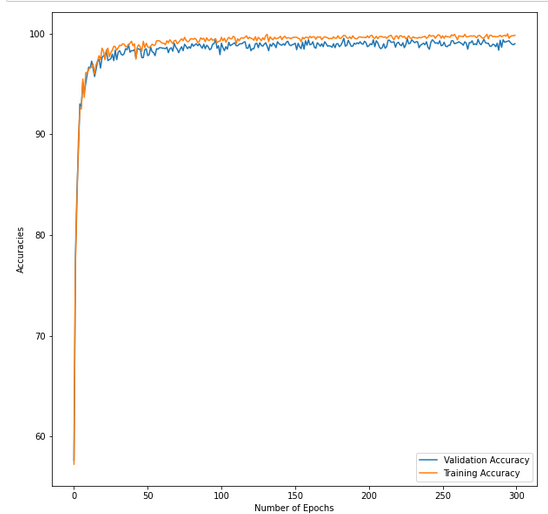
At the end of the day, I can see that my model has both very good training and validation accuracies per epochs. However, on test data it is not as good. Moreover, the validation loss is like double of the training loss.
What may be the reasons of having poor testing accuracy at the end? I will be glad if can some one explain what I am experiencing and recommend some solutions :)
Here is a picture of the training and validation losses.
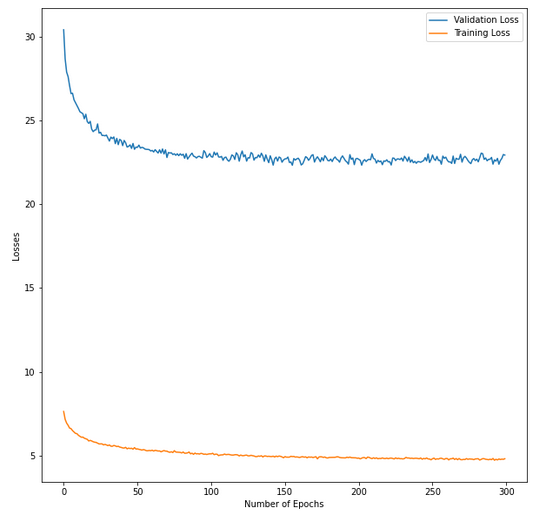
And here is a picture of the training and validation accuracies.
CodePudding user response:
I am pretty sure that the reason in Unrepresentative Validation Dataset.
An unrepresentative validation dataset means that the validation dataset does not provide sufficient information to evaluate the ability of the model to generalize. This may occur if the validation dataset has too few examples as compared to the training dataset. Make sure your training and testing data are picked randomly and represent as accurately as possible the same distribution and the real distribution.
CodePudding user response:
What is your data set sizes for training, test and validation?
Over-fitting seems to be the issue here, which you can check by using Regularization techniques like L1,L2 or Dropout.