I have a task of real time processing with structred spark streaming python so the first step was ingest csv file into kafka topic : Done
the second step was readStream from the topic kafka
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("subscribe", kafka_topic_name) \
.option("startingOffsets", "latest")\
.load()
then I use schema to cast my columns of my dataframe
from pyspark.sql.types import *
schema = StructType() \
.add("DriverId",IntegerType(),True) \
.add("time",TimestampType(),True) \
.add("Longitude",DoubleType(),True) \
.add("Latitude",DoubleType(),True) \
.add("SPEED",DoubleType(),True) \
.add("EngineSpeed",IntegerType(),True) \
.add("MAF",IntegerType(),True) \
.add("FuelType",IntegerType(),True) \
the second step was to display on console what I stream juste to see if I am on the right way :
query1 = df\
.writeStream\
.format("console")\
.outputMode("append")\
.option("truncate", False)\
.start()\
.awaitTermination()
but the result was a dataframe withe null values
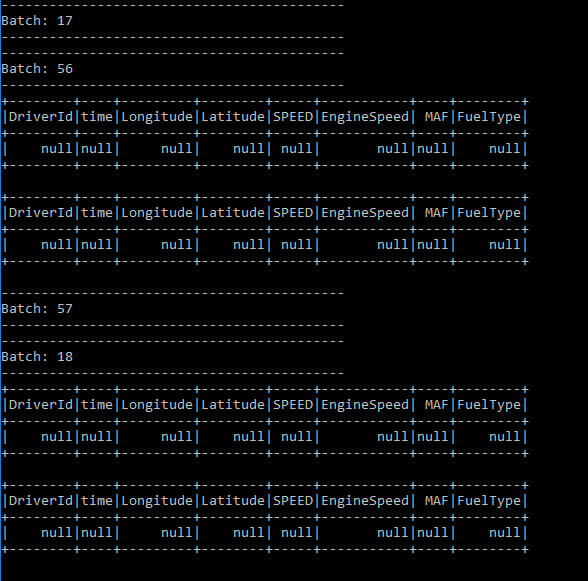
So , I have returned to schema and cast all column to stringType the result was :
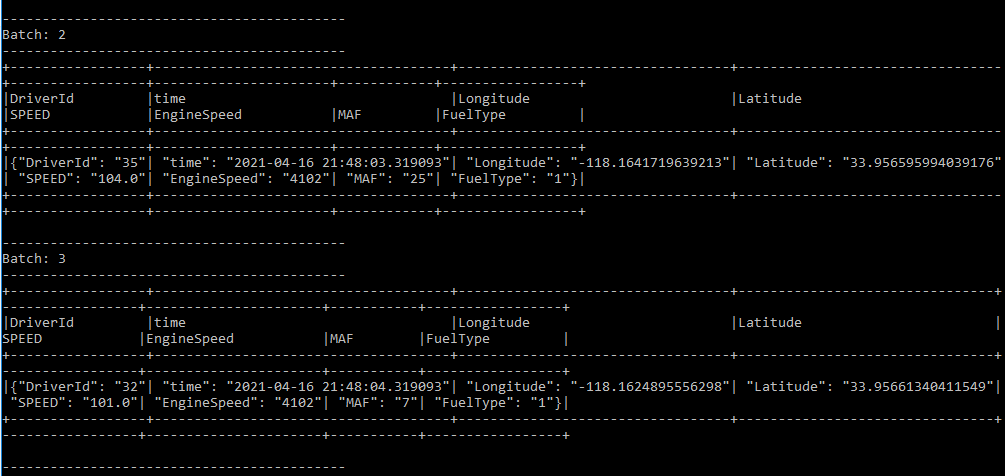
Something like a json !
**my Question is ** how can I cast right my dataframe and how to display under each column the value and note like format json
CodePudding user response:
When spark reads data from kafka, it creates a dataframe with 2 columns - key and value (These correspond to the key and value you send to kafka
The initial data type of these 2 columns is ByteType
You must convert them to StringType
df = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")Then, assuming your value column is a json string, you can convert it to a struct type with the schema you have specified
df = df.select(F.from_json(df.value,schema=my_schema).alias("value")) df = df.selectExpr("value.*")
More info is available here