I am trying to make plots with datashader. the data itself is a time series of points in polar coordiantes. i managed to transform them to cartesian coordianted(to have equal spaced pixles) and i can plot them with datashader.
the point where i am stuck is that if i just plot them with line() instead of points() it just connects the whole dataframe as a single line. i would like to plot the data of the dataframe group per group(the groups are the names in list_of_names ) onto the canvas as lines.
data can be found 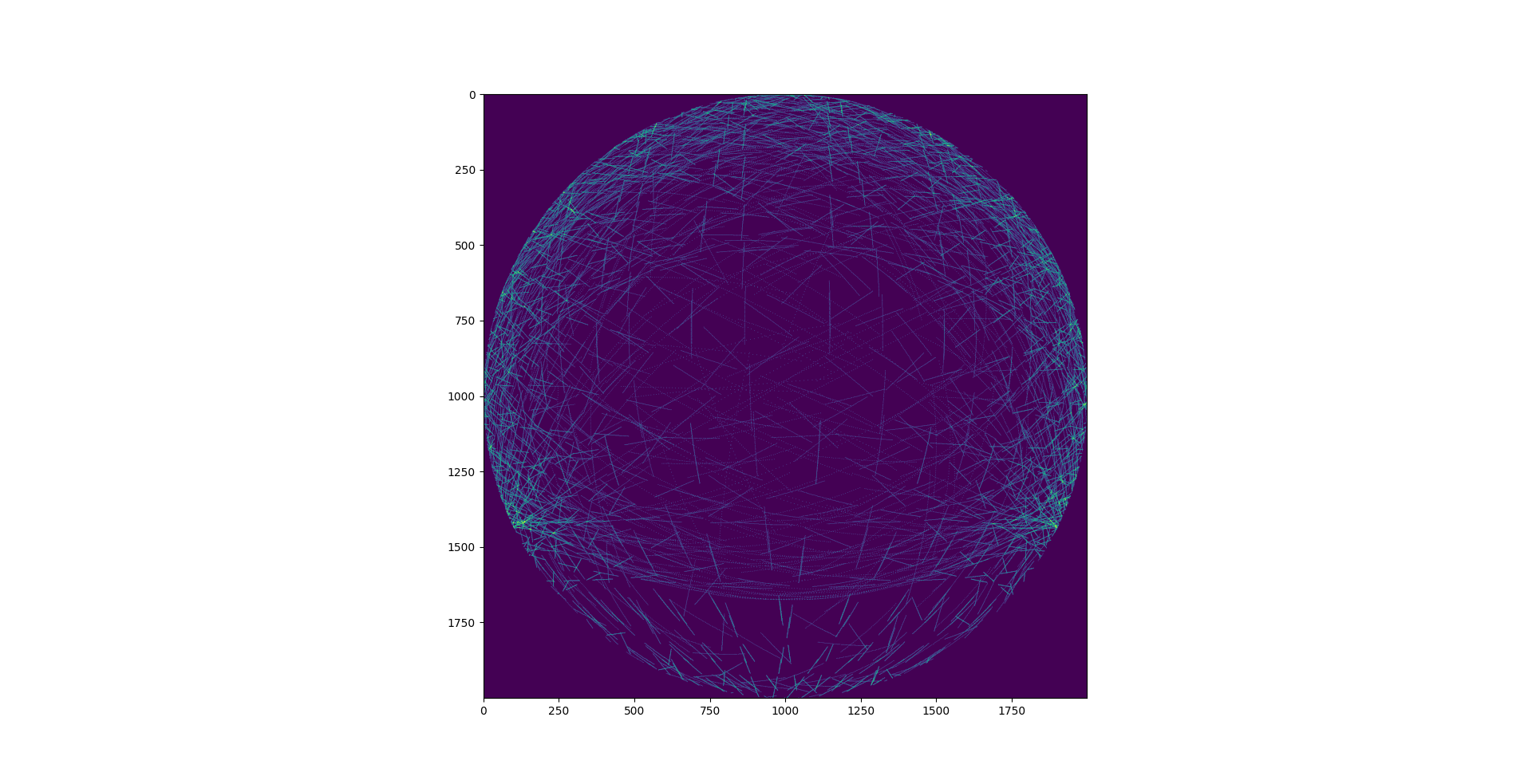
i get this kind of image with datashader
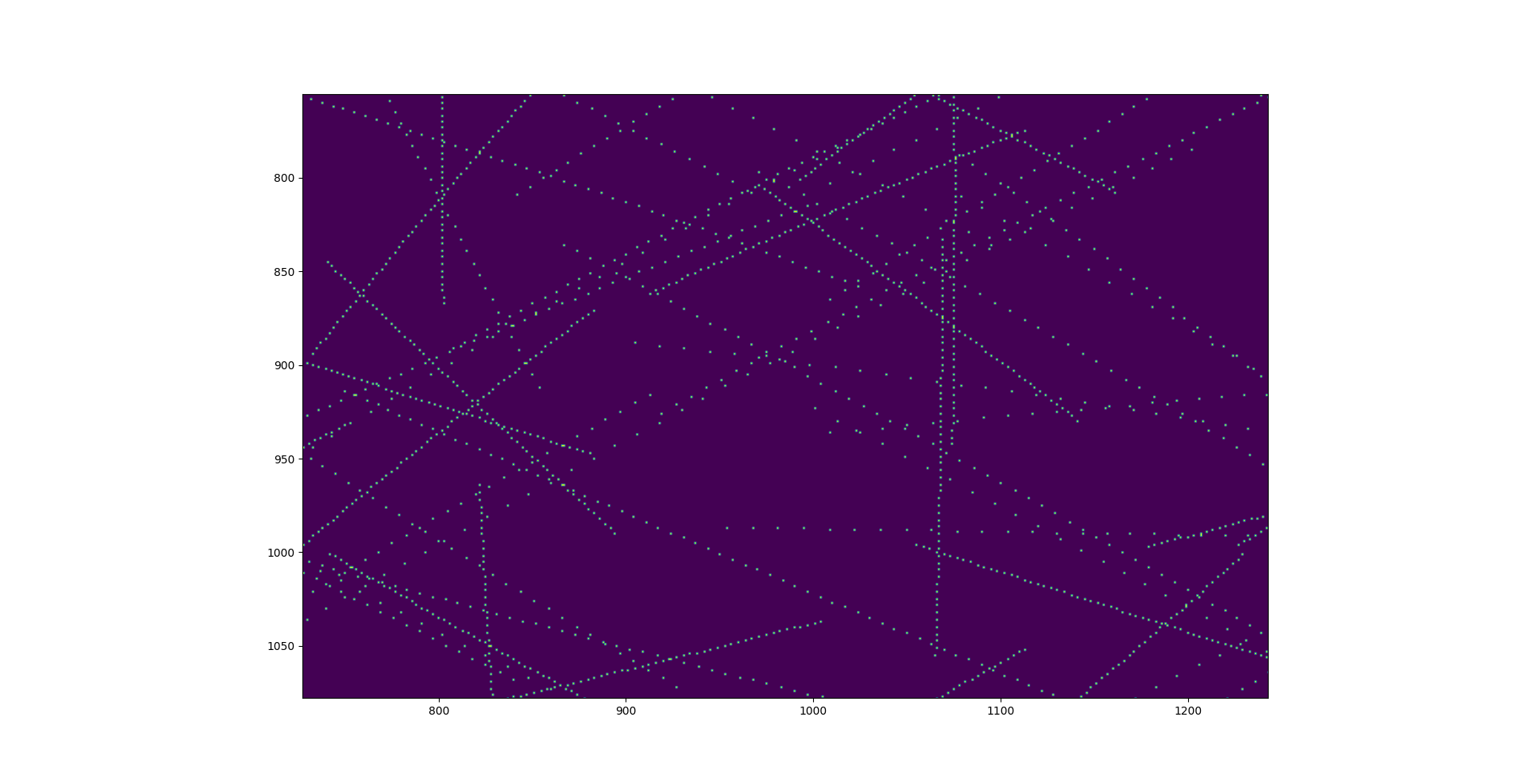
This is a zoomed in view of the plot generated with points() instead of line() the goal is to produce the same plot but with connected lines instead of points
import datashader as ds, pandas as pd, colorcet
import numby as np
df = pd.read_csv('file.csv')
print(df)
starlink_name = df.loc[:,'Name']
starlink_alt = df.loc[:,'starlink_alt']
starlink_az = df.loc[:,'starlink_az']
name = starlink_name.values
alt = starlink_alt.values
az = starlink_az.values
print(name)
print(df['Name'].nunique())
df['Date'] = pd.to_datetime(df['Date'])
for name, df_name in df.groupby('Name'):
print(name)
df_grouped = df.groupby('Name')
list_of_names = list(df_grouped.groups)
print(len(list_of_names))
#########################################################################################
#i want this kind of plot with connected lines with datashader
#########################################################################################
fig = plt.figure()
ax = fig.add_axes([0.1,0.1,0.8,0.8], polar=True)
# ax.invert_yaxis()
ax.set_theta_zero_location('N')
ax.set_rlim(90, 60, 1)
# Note: you must set the end of arange to be slightly larger than 90 or it won't include 90
ax.set_yticks(np.arange(0, 91, 15))
ax.set_rlim(bottom=90, top=0)
for name in list_of_names:
df2 = df_grouped.get_group(name)
ax.plot(np.deg2rad(df2['starlink_az']), df2['starlink_alt'], linestyle='solid', marker='.',linewidth=0.5, markersize=0.1)
plt.show()
print(df)
#########################################################################################
#transformation to cartasian coordiantes
#########################################################################################
df['starlink_alt'] = 90 - df['starlink_alt']
df['x'] = df.apply(lambda row: np.deg2rad(row.starlink_alt) * np.cos(np.deg2rad(row.starlink_az)), axis=1)
df['y'] = df.apply(lambda row: -1 * np.deg2rad(row.starlink_alt) * np.sin(np.deg2rad(row.starlink_az)), axis=1)
#########################################################################################
# this is what i want but as lines group per group
#########################################################################################
cvs = ds.Canvas(plot_width=2000, plot_height=2000)
agg = cvs.points(df, 'y', 'x')
img = ds.tf.shade(agg, cmap=colorcet.fire, how='eq_hist')
#########################################################################################
#here i am stuck
#########################################################################################
for name in list_of_names:
df2 = df_grouped.get_group(name)
cvs = ds.Canvas(plot_width=2000, plot_height=2000)
agg = cvs.line(df2, 'y', 'x')
img = ds.tf.shade(agg, cmap=colorcet.fire, how='eq_hist')
#plt.imshow(img)
plt.show()
CodePudding user response:
To do this, you need DataShader to "pick up the pen" as it were, by inserting a row of NaNs after each group. Not the slickest, but I think that's the current recommended solution.
Really simple, hacky example:
In [17]: df = pd.DataFrame({
...: 'name': list('AABBCCDD'),
...: 'x': np.arange(8),
...: 'y': np.arange(10, 18),
...: })
In [18]: df
Out[18]:
name x y
0 A 0 10
1 A 1 11
2 B 2 12
3 B 3 13
4 C 4 14
5 C 5 15
6 D 6 16
7 D 7 17
This block groups on the 'name' column, then reindexes each group to be one element longer than the original data:
In [20]: res = df.set_index('name').groupby('name').apply(
...: lambda x: x.reset_index(drop=True).reindex(np.arange(len(x) 1))
...: )
In [21]: res
Out[21]:
x y
name
A 0 0.0 10.0
1 1.0 11.0
2 NaN NaN
B 0 2.0 12.0
1 3.0 13.0
2 NaN NaN
C 0 4.0 14.0
1 5.0 15.0
2 NaN NaN
D 0 6.0 16.0
1 7.0 17.0
2 NaN NaN
You can plug this reindexed dataframe into datashader to have multiple disconnected lines in the result.
This is a still-open issue on the datashader repo, including additional examples and boilerplate code: https://github.com/holoviz/datashader/issues/257