I am using Databricks notebook to read and write the file into the same location. But when I write into the file I am getting a lot of files with different names. Like this:
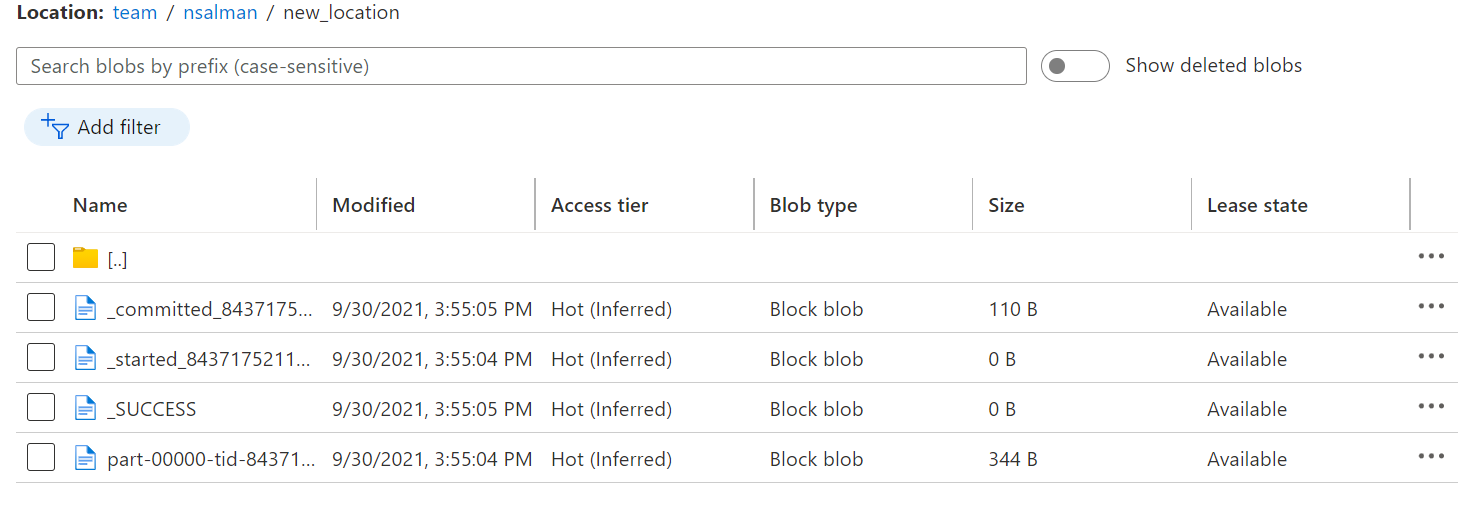
I am not sure why these files are created in the location I specified. Also, another file with the name "new_location" was created after I performed the write operation
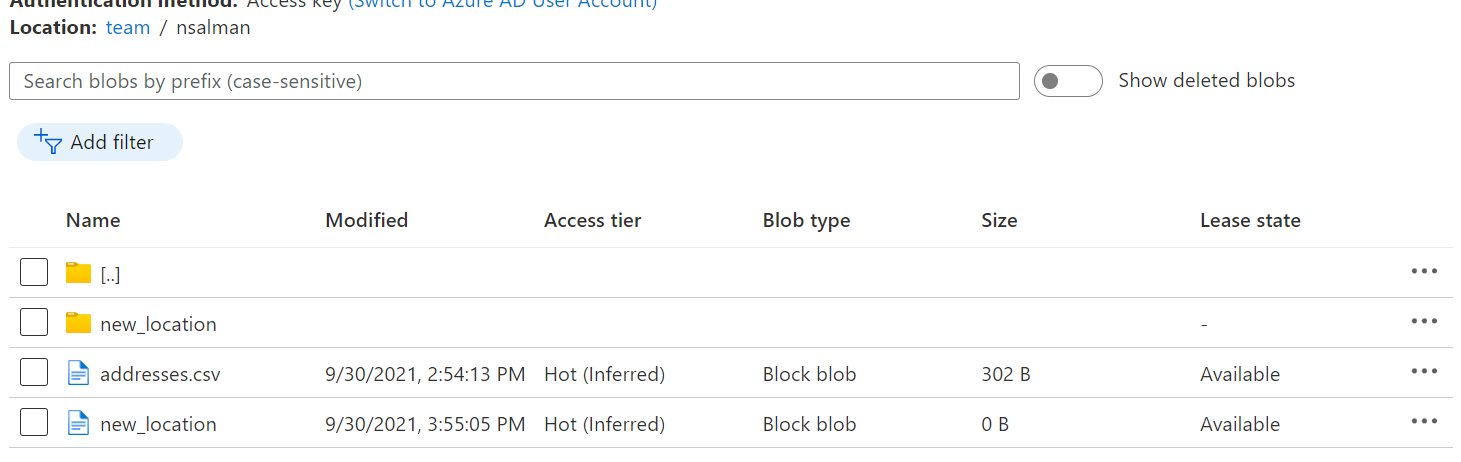
What I want is that after reading the file from Azure Blob Storage I should write the file into the same location with the same name as the original into the same location. But I am unable to do so. please help me out as I am new to Pyspark I have already mounted and now I am reading the CSV file store in an azure blob storage container. The overwritten file is created with the name "part-00000-tid-84371752119947096-333f1e37-6fdc-40d0-97f5-78cee0b108cf-31-1-c000.csv"
Code:
df = spark.read.csv("/mnt/ndemo/nsalman/addresses.csv", inferSchema = True)
df = df.toDF("firstName","lastName","street","town","city","code")
df.show()
file_location_new = "/mnt/ndemo/nsalman/new_location"
# write the dataframe as a single file to blob storage
df.write.format('com.databricks.spark.csv') \
.mode('overwrite').option("header", "true").save(file_location_new)
CodePudding user response:
Spark will save a partial csv file for each partition of your dataset. To generate a single csv file, you can convert it to a pandas dataframe, and then write it out.
Try to change these lines:
df.write.format('com.databricks.spark.csv') \
.mode('overwrite').option("header", "true").save(file_location_new)
to this line
df.toPandas().to_csv(file_location_new, header=True)
You might need to prepend "/dbfs/" to file_location_new for this to work.
Here is a minimal self-contained example that demonstrate how to write a csv file with pandas:
df = spark.createDataFrame([(1,3),(2,2),(3,1)], ["Testing", "123"])
df.show()
df.toPandas().to_csv("/dbfs/" "/mnt/ndemo/nsalman/" "testfile.csv", header=True)