I am fairly new to machine learning and deep learning. I am doing a student project wherein I am doing multiclassification image processing. Since, I do not have the recommended nVIDIA gpu for tensorflow (cannot buy it atm either), I am using Google colab instead and their virtual GPU.
I have mounted my gdrive to colab:
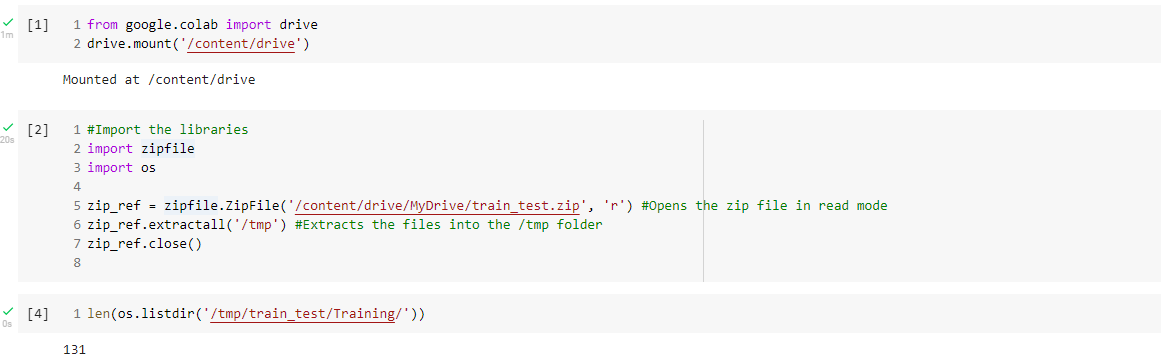
As you can see it shows 131 classes/subfolders in the training set. The 131 are names of different fruits - each fruit has 1 dedicated subfolder. There are a total of 40,000 images stored across these subfolders. Something as below:
Each fruit subfolder has images associated with the class and the images are named as 0_100.jpg, 1_100.jpg, 2_100.jpg.....
How do read and split these images into X-train and X_val and how do I create the associated y_train target name. Till date I have only worked with sklearn and keras datasets in jupyter lab, which are already sorted and named and I only had to import them.
Since, the dataset is downloaded from kaggle, do you suppose it is better to directly connect to kaggle from colab and create a json file?...like in this link: https://towardsdatascience.com/an-informative-colab-guide-to-load-image-datasets-from-github-kaggle-and-local-machine-75cae89ffa1e
Please can someone suggest how to do this or point me to some relevant examples...much appreciated.
CodePudding user response:
You can use DataLoader from PyTorch, for example:
import torch
import torchvision
from torchvision import transforms
train_transforms = transforms.Compose([
# ...
transforms.ToTensor() ])
train_dir = '/train_test/Training/'
# As you are going to split Training set into Train and Val sets, "Training" is your full_dataset
# Loading dataset from directory
full_dataset = torchvision.datasets.ImageFolder(train_dir, train_transforms)
# Splitting into Train and Val
train_size = int(0.8 * len(full_dataset))
val_size = len(full_dataset) - val_size
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])
# Creating a data_loader
train_dataloader = torch.utils.data.DataLoader( train_dataset )
val_dataloader = torch.utils.data.DataLoader( val_dataset )
In case you have you dataset splitted into Train and Val by other methods or don't want to use Val set, using torchvision.datasets.ImageFolder you load train_dataset and create a data loader directly and skip splitting part.
It automatically creates X (input image) and Y (labels) sets. Then, on train phase you can use train_dataloader in the following way:
# ...
for inputs, labels in tqdm(train_dataloader):
inputs = inputs.to(device) # Your X-train
labels = labels.to(device) # Your y_train
# ...
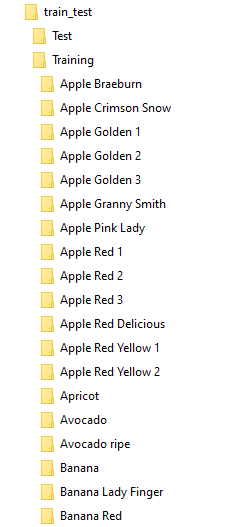
It works in case you have following structure (if I got the way your data is stored clearly):
|-train_test
|-Test
|-Training
|-Apple Braeburn
| |-0_100.jpg
| |-1_100.jpg
| |-...
|-Apple Crimson Snow
| |-0_100.jpg
| |-1_100.jpg
| |-...
|-...