This is the input table

Output Table should be
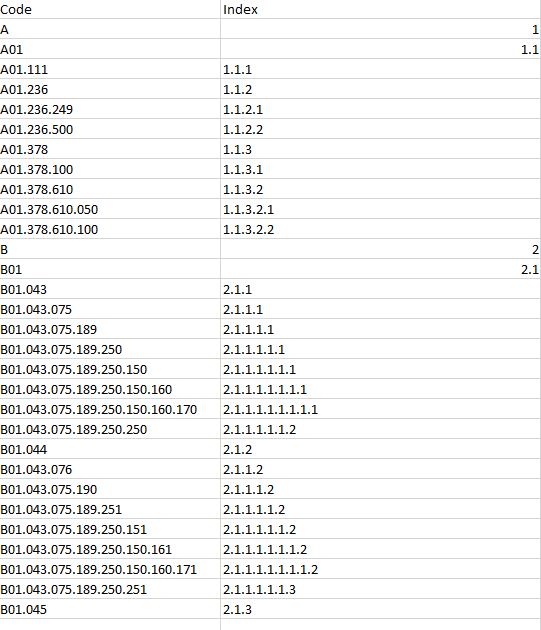
Input table in text format
Code Index
A
A01
A01.111
A01.236
A01.236.249
A01.236.500
A01.378
A01.378.100
A01.378.610
A01.378.610.050
A01.378.610.100
B
B01
B01.043
B01.043.075
B01.043.075.189
B01.043.075.189.250
B01.043.075.189.250.150
B01.043.075.189.250.150.160
B01.043.075.189.250.150.160.170
B01.043.075.189.250.250
B01.044
B01.043.076
B01.043.075.190
B01.043.075.189.251
B01.043.075.189.250.151
B01.043.075.189.250.150.161
B01.043.075.189.250.150.160.171
B01.043.075.189.250.251
B01.045
CodePudding user response:
That's a good question. I've tried to play with the Series.str class of pandas but I have no idea how to deal with this in a vector-computational way since the number of hierarchy levels may be very large.
Here I give a simple for-loop method. It might be very slow if your data is very large, but it does work at least.
I've OCRed the data from your pic, and I suggest you to modify your data as follow first(To separate the first two levels, using A vs A01 is not a good idea, use A vs A.01 instead):
data = """A
A.01
A.01.111
A.01.236
A.01.236.249
A.01.236.500
A.01.378
A.01.378.100
A.01.378.610
A.01.378.610.050
A.01.378.610.100
B.
B.01
B.01.043
B.01.043.075
B.01.043.075.189
B.01.043.075.189.250
B.01.043.075.189.250.150
B.01.043.075.189.250.150.160
B.01.043.075.189.250.150.160.170
B.01.043.075.189.250.250
B.01.043.075.189.250.250.200
B.01.043.075.189.250.250.250
B.01.043.075.189.250.250.250.250
B.01.043.075.189.250.250.400
B.01.043.075.189.250.750
B.01.043.075.189.250.750.550
B.01.043.075.189.250.750.750
B.01.043.075.189.250.750.800
B.01.043.075.189.275
"""
And then you may use collections.OrderDict since this can work well in Python<=3.6:
from collections import OrderedDict
hierarchy = OrderedDict()
for line in data.splitlines():
this_hier = hierarchy
indices = []
for hier in line.split("."):
if not hier in this_hier:
this_hier.update({hier: OrderedDict()})
#Remove ` 1` if you'd like indices start from 0
indices.append(list(this_hier.keys()).index(hier) 1)
this_hier = this_hier[hier]
print(".".join(map(str, indices)))
The output is:
1
1.1
1.1.1
1.1.2
1.1.2.1
1.1.2.2
1.1.3
1.1.3.1
1.1.3.2
1.1.3.2.1
1.1.3.2.2
2.1
2.2
2.2.1
2.2.1.1
2.2.1.1.1
2.2.1.1.1.1
2.2.1.1.1.1.1
2.2.1.1.1.1.1.1
2.2.1.1.1.1.1.1.1
2.2.1.1.1.1.2
2.2.1.1.1.1.2.1
2.2.1.1.1.1.2.2
2.2.1.1.1.1.2.2.1
2.2.1.1.1.1.2.3
2.2.1.1.1.1.3
2.2.1.1.1.1.3.1
2.2.1.1.1.1.3.2
2.2.1.1.1.1.3.3
2.2.1.1.1.2