I have an Excel worksheet which is 250 rows by 10 column of data. My dependent variable is n_nnld_trp and I am trying to find which independent variables are highly correlated with it to use in a linear regression model.

I want to make a table like this to summarize the correlation data as well as identify any cases of multi-collinearity using the equation in the picture:
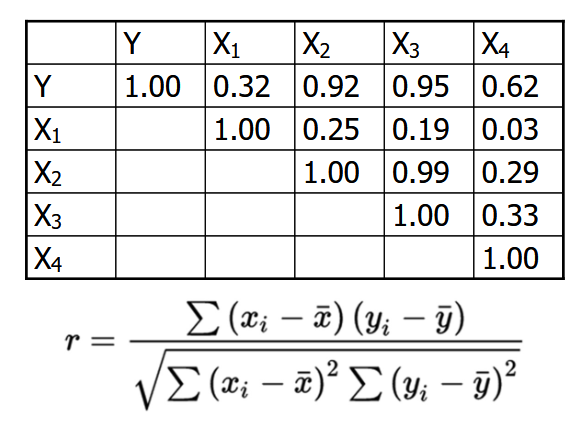
So far, I managed to use a pivot table to get the mean of each row with my dependent variable being n_hhld_trp:
trip_mean = pd.pivot_table(read_excel, index=['n_hhld_trip'],
aggfunc=np.mean)
print(trip_mean.head())
I'm finding it hard to make the table of correlation as shown above and I would welcome and appreciate any help.
CodePudding user response:
Numpy has all necessary functions to calculate any of such common things so to calculate r the dataframe the simplest way is:
import numpy as np
r = np.corrcoef(df.values)
Alternatively, to calculate between individual pairs of variables you can just feed a smaller array to corrcoef function or just calculate it directly:
r = np.cov(df.n_nnld_trp.values, df.other_col.values) / (np.std(df.n_nnld.trp.values) * np.std(df.other_col.values))
CodePudding user response:
After a few hours of digging around I got it to how I wanted to present it. For anyone wanting to do something similar, see code below:
import pandas as pd
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
pearson_correlation = read_excel.corr(method='pearson')
print(pearson_correlation)
{kind=link}