I have n indices that result in n(n-1)/2 pairwise combinations, e.g. for n=3
(i,j,k) -> (i,j), (i,k), (j,k)
Now for each of these pairs I know the possibilities, e.g.
(i,j) = (1,2), (1,3), (2,2)
(i,k) = (2,2), (1,2), (2,4)
(j,k) = (1,2), (4,3), (2,2)
In other words, in some combination (i,j,k) we must have that (i,j) is (1,2) or (1,3) or (2,2) and the same for the other pairs. I wish to construct all combinations that are possible, so in the above example there are only two possible combinations:
(i,j,k) = (2,2,2)
(i,j,k) = (1,2,2)
I have currently implemented this procedure as follows:
import numpy as np
ij = np.array(([1,2], [1,3], [2,2]))
ik = np.array(([2,2], [1,2], [2,4]))
jk = np.array(([1,2], [4,3], [2,2]))
possibilities = []
possible_i = np.union1d(ij[:,0], ik[:,0])
possible_j = np.union1d(ij[:,1], jk[:,0])
possible_k = np.union1d(ik[:,1], jk[:,1])
for i in possible_i:
for j in possible_j:
if ([i,j] == ij).all(1).any():
for k in possible_k:
if (([i,k] == ik).all(1).any() and
([j,k] == jk).all(1).any()):
print(i,j,k)
Although this works and can be easily adapted to any n, it does not seem very efficient to me as it for example checks the combinations:
1 2 2
1 2 2
1 2 3
1 2 4
1 3 2
1 3 3
1 3 4
2 2 2
2 2 2
2 2 3
2 2 4
Of course, we know after checking that (i,j,k) = (i,2,3) is not valid, we don't have to recheck the other combinations of this form. Is there a more efficient way to tackle this task (that also applies works for higher n)?
CodePudding user response:
We represent possible combinations by lists of length n. The indices for which we haven't got any information yet will contain None.
Each turn will treat a pairs of indices, and check all the rules for this pair.
If the first value of the pair exists in a possible combination of the previous turn, and the second one has never been touched (so is None), we add this as a new possible combination for this turn.
If both values exist in a previous combination, this confirms that it may be valid, we add it as well.
We can just abandon the results of the previous turn, as combinations that we previously considered as possible and haven't been validated on this turn are impossible.
So, the code:
from itertools import combinations
def possible_combs(n, pairs_list):
# Pairs of indices, generated in the same order as the lists of allowed pairs
indices = combinations(range(n), r=2)
# Current list of possible combinations. None means no information for this index
current = [[None] * n]
for (first, last), allowed in zip(indices, pairs_list):
previous = current
current = []
# Iteration on each allowed pair for the current pair of indices
for i, j in allowed:
for comb in previous:
if comb[first] is None:
# We can have previous combinations having None for the starting index
# only during the first step. In this case, we create the path.
new = comb[:]
new[first] = i
new[last] = j
current.append(new)
if comb[first] == i:
if comb[last] is None:
# A path leading to a yet unknown value, we add it
new = comb[:]
new[last] = j
current.append(new)
elif comb[last] == j:
# A valid path, we keep it
current.append(comb[:])
# At this point, any previous combination that didn't satisfy
# any rule of this turn hasn't made it
# to current and will be forgotten...
return current
Sample run on your data:
possible_combs(3, [[(1,2), (1,3), (2,2)],
[(2,2), (1,2), (2,4)],
[(1,2), (4,3), (2,2)]])
Output:
[[2, 2, 2], [1, 2, 2]]
Note that it makes no hypothesis on the number of rules for each pair of indices.
CodePudding user response:
The problem can be depicted as a graph, where nodes are organised in columns:
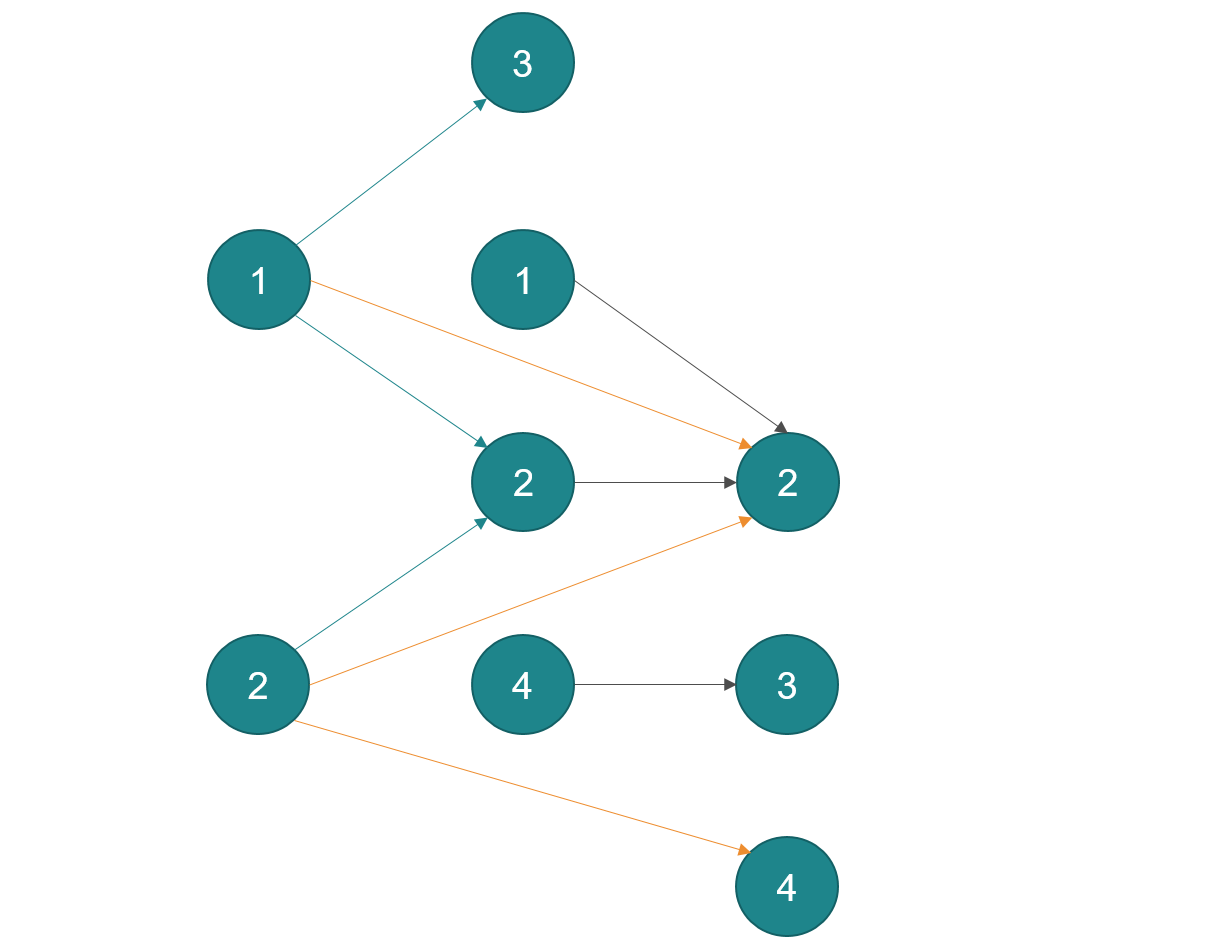
A node is uniquely identified by the column it is in and the value it has.
A solution can be constructed by taking the possible edges between the first two columns, and then extending those edges to paths of size 2 where possible, involving the nodes of the relevant column, then extending again to size 3, involving the next column, ...etc. Each time a node is added to a path, it must be verified that all previous nodes in the path connect to that new node.
To do this efficiently I would suggest using an adjacency list type of data structure, or in fact an adjacency set, so that you can quickly fetch which nodes are reachable in a given column from a given node in another column. These sets of neighbors can be intersected so to be left with connections that fulfil all constraints.
I would define the input constraints as a dictionary, so there is no doubt as to what i and j are (the columns) for a given list of pairs. So the example input would be this dictionary:
{
(0, 1): [(1,2), (1,3), (2,2)],
(0, 2): [(2,2), (1,2), (2,4)],
(1, 2): [(1,2), (4,3), (2,2)]
}
Code:
from collections import defaultdict
def solve(constraints):
# n is the size of each output tuple
n = max(b for _, b in constraints) 1
# convert contraints to adjacency sets
graph = {}
for key, pairs in constraints.items():
dct = defaultdict(set)
for a, b in pairs:
dct[a].add(b)
graph[key] = dct
paths = constraints[(0, 1)]
for j in range(2, n):
newpaths = []
for path in paths:
additions = graph[(0, j)][path[0]]
for i in range(1, len(path)):
additions &= graph[(i, j)][path[i]]
if not additions: # quick exit
break
newpaths.extend((*path, num) for num in additions)
paths = newpaths
return paths
Call like this:
constraints = {
(0, 1): [(1,2), (1,3), (2,2)],
(0, 2): [(2,2), (1,2), (2,4)],
(1, 2): [(1,2), (4,3), (2,2)]
}
result = solve(constraints)
print(result)
Output:
[(1, 2, 2), (2, 2, 2)]
CodePudding user response:
You can use recursion while tracking the previous inclusion of values associated with the tuple pairs in your input. This way, the combinations can be more efficiently produced up-front, without having to filter an entire set of combinations afterwards:
from collections import defaultdict
d, d1 = {(0, 1): [(1, 2), (1, 3), (2, 2)], (0, 2): [(2, 2), (1, 2), (2, 4)], (1, 2): [(1, 2), (4, 3), (2, 2)]}, defaultdict(list)
for (a, b), j in d.items():
d1[a].extend((l:=list(zip(*j)))[0])
d1[b].extend(l[1])
def combos(p, c = {}):
if not p:
yield [*c.values()]
else:
for i in set(d1[p[0]]):
if len(c) < 1 or all((b, i) in d[(a, p[0])] for a, b in c.items()):
yield from combos(p[1:], {**c, p[0]:i})
print(list(combos([*{i for k in d for i in k}])))
Output:
[[1, 2, 2], [2, 2, 2]]