I have user-defined tags in the content, and have keyword tags that has corresponding id number on it
const tags = ["<i>", "<c>", "<b1>", "<b2>", "<b3>"];
keyword tags e.g. "<key2>", "<key10>"
I have to remove the leading and trailing spaces, because I need to split it by word.
Here's is my sample content:
let content =
`<b1> <c> "The Modern Amphibians" </c> </b1>
Modern <b>amphibians </b> have a simplified <key2>anatomy </key2> compared to their ancestors due to <i> paedomorphosis</i>.
Caused by two evolutionary trends: <b2> miniaturization </b2> and an unusually.
Don’t think that this term’s work will be <key23> a piece of cake </key23>`
The expected output would be (leading & trailing space(s) removed)
let output =
`<b1><c>"The Modern Amphibians"</c></b1>
Modern <b>amphibians</b> have a simplified <key2>anatomy</key2> compared to their ancestors due to <i>paedomorphosis</i>.
Caused by two evolutionary trends: <b2>miniaturization</b2> and an unusually.
Don’t think that this term’s work will be <key23>a piece of cake</key23>`
I have tried to make my own regex, starting with the c tag but I'm not sure if this is proper, since I just need only to remove the spaces, but my regex is including the tag.
const customRegex = \((<c>\s)|(\s<\/c>))\g.
Someone can help. thanks.
CodePudding user response:
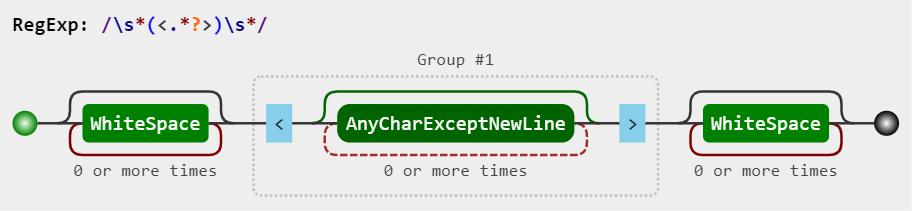
You can use regex /\s*(<.*?>)\s*/g
let content = `<b1> <c> "The Modern Amphibians" </c> </b1>
Modern <b>amphibians </b> have a simplified <key2>anatomy </key2> compared to their ancestors due to <i> paedomorphosis</i>.
Caused by two evolutionary trends: <b2> miniaturization </b2> and an unusually.
Don’t think that this term’s work will be <key23> a piece of cake </key23>`;
const result = content.replace(/\s*(<.*?>)\s*/g, "$1");
console.log(result);CodePudding user response:
You may try (<[^<>\/] >)\s |\s (<\/[^<>] >).
This ensures to only remove spaces either after an opening tag (e.g. <s>) or before a closing tag (e.g. </s>)
const regex = /(<[^<>\/] >)\s |\s (<\/[^<>] >)/g;
const content =
`<b1> <c> "The Modern Amphibians" </c> </b1>
Modern <b>amphibians </b> have a simplified <key2>anatomy </key2> compared to their ancestors due to <i> paedomorphosis</i>.
Caused by two evolutionary trends: <b2> miniaturization </b2> and an unusually.
Don’t think that this term’s work will be <key23> a piece of cake </key23>`;
console.log(content.replace(regex, '$1$2'));CodePudding user response:
let output = content.replaceAll(/(\s)?(\<\/?\w \>)(\s)?/g, '$2')
This should work
CodePudding user response:
Your RegEx approach is correct, and here's a feature that'll help: $1..$9
This feature allows you to "capture" specific parts of a RegExp you matched and reference it when replacing:
const regex = /(/w )/s (/w )/;
const string = "John Smith";
string.replace(regex, "$2, $1)); //" Smith, John"
To use it in your case, we'll need a regex that would match any tag and replace it with a no-whitespace version:
const regex = (<. >)\s (<. >)/g;
const string = "<b1> <c> abc </c> </b1>";
string.replace(regex, "$1$2");