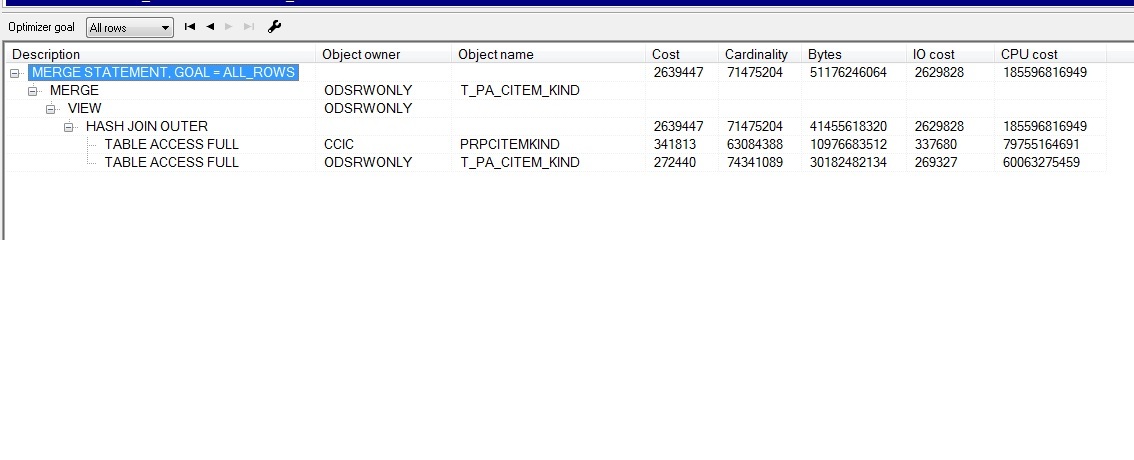
The code is as follows: The MERGE INTO T_PA_CITEM_KIND t_pa USING CCIC. PRPCITEMKIND t_p ON (t_pa. POLICYNO=t_p. POLICYNO AND t_pa. SEQNO=t_p. ITEMKINDNO) The WHEN MATCHED THEN The UPDATE The SET t_pa. RISKCODE=t_p. RISKCODE , t_pa. CLAUSENAME=t_p. KINDNAME , t_pa. KINDNAME=t_p. ItemDetailName , t_pa. STARTDATE=t_p. STARTDATE , t_pa. STARTHOUR=t_p. STARTHOUR T_pa), ENDDATE=t_p, ENDDATE , t_pa. ENDHOUR=t_p. ENDHOUR , t_pa. CURRENCY=t_p. CURRENCY , t_pa. CALCULATEFLAG=t_p. CALCULATEFLAG , t_pa. UNITAMOUNT=t_p. UNITAMOUNT , t_pa. QUANTITY=t_p. QUANTITY , t_pa. RATE=t_p. RATE , t_pa. SHORTRATE=t_p. SHORTRATE , t_pa. SHORTRATEFLAG=t_p. SHORTRATEFLAG , t_pa. AMOUNT=t_p. AMOUNT , t_pa. PREMIUM=t_p. PREMIUM , t_pa. KINDVAT=t_p. KINDVAT , t_pa. TNIPREMIUM=t_p. TNIPREMIUM , t_pa. VATRATETYPE=t_p. VATRATETYPE , t_pa. FLAG=t_p. FLAG WHEN NOT MATCHED THEN INSERT (POLICYNO, SEQNO, ITEMTYPE, REL_REF_SEQNO, RISKCODE, CLAUSECODE, CLAUSENAME, KINDCODE KINDNAME, STARTDATE, ENDDATE, STARTHOUR, ENDHOUR, CURRENCY, CALCULATEFLAG, UNITAMOUNT , UNITPREMIUM, QUANTITY, RATE, SHORTRATE SHORTRATEFLAG, AMOUNT of PREMIUM, KINDVAT , TNIPREMIUM VATRATETYPE, FLAG, ORIGININPUTFLAG) VALUES (t_p POLICYNO T_p. ITEMKINDNO The NULL The NULL T_p. RISKCODE The null T_p. KINDNAME The null T_p. ItemDetailName T_p. STARTDATE T_p. STARTHOUR T_p. ENDDATE T_p. ENDHOUR T_p. CURRENCY T_p. CALCULATEFLAG T_p. UNITAMOUNT The NULL T_p. QUANTITY T_p. RATE T_p. SHORTRATE T_p. SHORTRATEFLAG T_p. AMOUNT T_p. PREMIUM T_p. KINDVAT T_p. TNIPREMIUM T_p. VATRATETYPE T_p. FLAG , 'Y') Execution plan is as follows:
The two tables data volume is more than 40 million, update, and insert the amount of data is quite large, the actual implementation process there is a time mark, no, so I didn't add,
Execution time is too long, can you tell me what's the optimized method, both have a primary key, relevance is associated with a primary key, Online, etc., thank you!
CodePudding user response:
If you use the associated field is target table's primary key field , then there may be several improvement measures: 1, look at the two table join field types inconsistent? If not consistent, then into a temporary table field type consistent with the target table, or modify the table definition, or use the corresponding function to modify a temporary table join condition; 2, if not 1, you can try two table statistics collection: exec dbms_stats. Gather_table_stats (' user name 'and' table ', cascade=& gt; True, method_opt=& gt; 'for all indexed columns repeat') 3, if after the above adjustment is slow, unable to adjust the execution plan of the HASH JOIN into NESTED LOOPS, then add to alert, and behind the merge keyword: merge/* + use_nl_with_index (t_pa) */ 4, if after 3 doesn't work, then continue to add hint after statements and execution plan