I have a txt file that looks like this
1000 lewis hamilton 36
1001 sebastian vettel 34
1002 lando norris 21
i want them to look like this
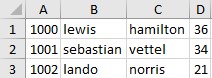
I tried the solution in here but it gave me a blank excel file and error when trying to open it
There is more than one million lines and each lines contains around 10 column
And one last thing i am not 100% sure if they are tab elimited because some columns looks like they have more space in between them than the others but when i press to backspace once they stick to each other so i guess it is
CodePudding user response:
you can use pandas read_csv for read your txt file and then save it like an excel file with .to_excel
df = pd.read_csv('your_file.txt' , delim_whitespace=True)
df.to_excel('your_file.xlsx' , index = False)
here some documentation :
pandas.read_csv : https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
.to_excel : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_excel.html
CodePudding user response:
If you're not sure about how the fields are separated, you can use '\s' to split by spaces.
import pandas as pd
df = pd.read_csv('f1.txt', sep="\s ", header=None)
# you might need: pip install openpyxl
df.to_excel('f1.xlsx', 'Sheet1')
Example of randomly separated fields (f1.txt):
1000 lewis hamilton 2 36
1001 sebastian vettel 8 34
1002 lando norris 6 21
If you have some lines having more columns than the first one, causing:
ParserError: Error tokenizing data. C error: Expected 5 fields in line 5, saw 6
You can ignore those by using:
df = pd.read_csv('f1.txt', sep="\s ", header=None, error_bad_lines=False)
This is an example of data:
1000 lewis hamilton 2 36
1001 sebastian vettel 8 34
1002 lando norris 6 21
1003 charles leclerc 1 3
1004 carlos sainz ferrari 2 2
The last line will be ignored:
b'Skipping line 5: expected 5 fields, saw 6\n'